Friendli Container:Serve your LLMs with Friendli Engine
in your private environment
Supercharge your LLM compute with
Friendli Container’s accelerated inference solutions
Friendli Container simplifies the process of containerizing your generative model for efficient serving.
Our engine ensures better user experiences while cutting down on inference costs.
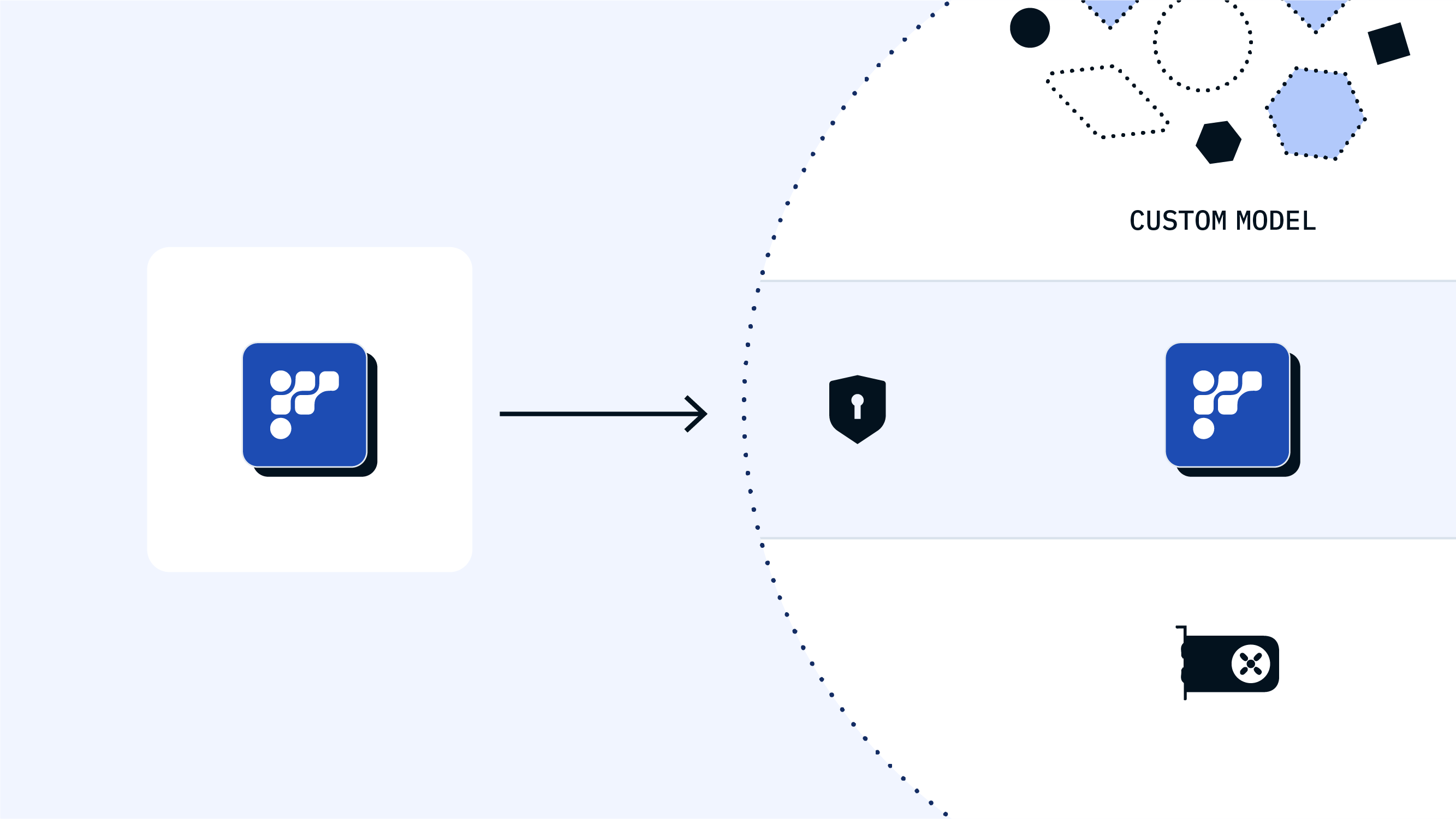
With Friendli Container, you can perform high-speed LLM inferencing in a secure and private environment.
Full control of your data
Maximum privacy and security
Integration with internal systems
Save on huge GPU costs
Generative AI models with Container
The current version of Friendli Containers supports all major generative language models, including Llama 2, Falcon, MPT, and Dolly.
Tell us which generative AI models you would like us to add: support@friendli.ai

Chatbot Company A
LLM-powered chatbot company A cuts GPU costs by more than 50% instantly.
PROBLEM
Processing ~0.5 trillion tokens per month incurs high H100 GPU costs.
SOLUTION
Uses Friendli Container for LLM serving.
RESULTS
Cuts costs by more than 50% instantly.
Zeta 2.0 blooms with Friendli Container
PROBLEM
The generative model is expensive to run.
SOLUTION
Use Friendli Container for Zeta.
RESULTS
Cuts costs by 50%.
How to use Friendli Container
Friendli Containers enable you to effortlessly deploy your generative AI model on your own machine.
Visit our documentation to learn how to start running a Friendli Container.
Frequently asked questions
How does the pricing for Friendli Container work?
Friendli Container offers a flexible pricing structure. Please contact us at sales@friendli.ai for a custom quote. You can also try the four-week free trial to experience the full capabilities of Friendli Container. Serve your LLM model in your development environment without any charges.
Can I use Friendli Container for enterprise purposes?
Yes, Friendli Container offers an Enterprise version tailored to the needs of larger organizations. To access the Enterprise version and discuss pricing options, please contact our sales team at sales@friendli.ai.
Is my data secure when using Friendli Container?
Yes, ensuring the security and privacy of your data is our top priority. Friendli Container allows you to serve your LLM in a secure and private environment, safeguarding your sensitive information throughout the process. We adhere to industry-standard security protocols and continuously update our platform to address any potential vulnerabilities.
How much performance gain should I expect using Friendli Container?
Our engine provides 10x faster token generation and 5x faster initial response time compared to vLLM. The actual performance may change depending on your GPU, LLM model, and traffic. Please contact contact@friendli.ai to get help measuring your performance gain in your environment.
Experience superior inference performance
for all kinds of LLMs with Friendli Engine.
Learn moreFriendli DNN library
Optimized GPU kernels for generative AI
Iteration batching (aka continuous batching)
We invented this technique and have further innovated it.
Learn moreSupports a wide range of generaitve AI models
See full list