Multimodal performance

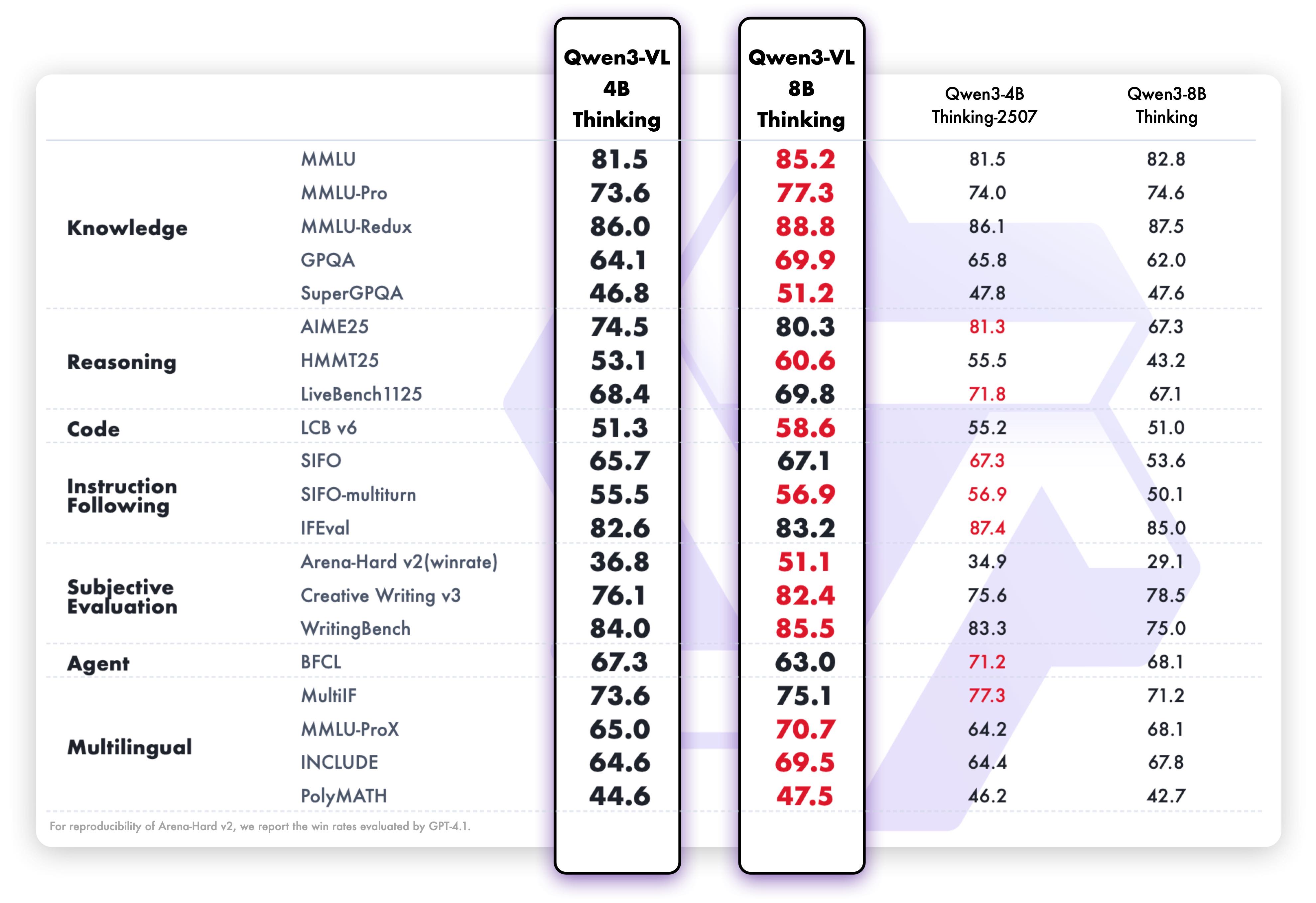
Pure text performance
Quickstart
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
The code of Qwen3-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
pip install git+https://github.com/huggingface/transformers
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
Here we show a code snippet to show you how to use the chat model with transformers:
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-4B-Thinking", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Thinking")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Generation Hyperparameters
VL
export greedy='false'
export top_p=0.95
export top_k=20
export repetition_penalty=1.0
export presence_penalty=0.0
export temperature=1.0
export out_seq_length=40960
Text
export greedy='false'
export top_p=0.95
export top_k=20
export repetition_penalty=1.0
export presence_penalty=1.5
export temperature=1.0
export out_seq_length=32768 (for aime, lcb, and gpqa, it is recommended to set to 81920)
Citation
If you find our work helpful, feel free to give us a cite.
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{Qwen2.5-VL,
title={Qwen2.5-VL Technical Report},
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
journal={arXiv preprint arXiv:2502.13923},
year={2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}
