Model Summary
Phi-4-multimodal-instruct is a lightweight open multimodal foundation
model that leverages the language, vision, and speech research
and datasets used for Phi-3.5 and 4.0 models. The model processes text,
image, and audio inputs, generating text outputs, and comes with
128K token context length. The model underwent an enhancement process,
incorporating both supervised fine-tuning, direct preference
optimization and RLHF (Reinforcement Learning from Human Feedback)
to support precise instruction adherence and safety measures.
The languages that each modal supports are the following:
- Text: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish,
French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian,
Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian
- Vision: English
- Audio: English, Chinese, German, French, Italian, Japanese, Spanish, Portuguese
📰 Phi-4-multimodal Microsoft Blog
📖 Phi-4-multimodal Technical Report
🏡 Phi Portal
👩🍳 Phi Cookbook
🖥️ Try It on Azure,
GitHub,
Nvidia,
Huggingface playgrounds
📱Huggingface Spaces
Thoughts Organizer,
Stories Come Alive,
Phine Speech Translator
Watch as Phi-4 Multimodal analyzes spoken language to help plan a trip to Seattle, demonstrating its advanced audio processing and recommendation capabilities.
See how Phi-4 Multimodal tackles complex mathematical problems through visual inputs, demonstrating its ability to process and solve equations presented in images.
Explore how Phi-4 Mini functions as an intelligent agent, showcasing its reasoning and task execution abilities in complex scenarios.
Intended Uses
Primary Use Cases
The model is intended for broad multilingual and multimodal commercial and research use . The model provides uses for general purpose AI systems and applications which require
- Memory/compute constrained environments
- Latency bound scenarios
- Strong reasoning (especially math and logic)
- Function and tool calling
- General image understanding
- Optical character recognition
- Chart and table understanding
- Multiple image comparison
- Multi-image or video clip summarization
- Speech recognition
- Speech translation
- Speech QA
- Speech summarization
- Audio understanding
The model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
Use Case Considerations
The model is not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models and multimodal models, as well as performance difference across languages, as they select use cases, and evaluate and mitigate for accuracy, safety, and fairness before using within a specific downstream use case, particularly for high-risk scenarios.
Developers should be aware of and adhere to applicable laws or regulations (including but not limited to privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
Release Notes
This release of Phi-4-multimodal-instruct is based on valuable user feedback from the Phi-3 series. Previously, users could use a speech recognition model to talk to the Mini and Vision models. To achieve this, users needed to use a pipeline of two models: one model to transcribe the audio to text, and another model for the language or vision tasks. This pipeline means that the core model was not provided the full breadth of input information – e.g. cannot directly observe multiple speakers, background noises, jointly align speech, vision, language information at the same time on the same representation space.
With Phi-4-multimodal-instruct, a single new open model has been trained across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. The model employed new architecture, larger vocabulary for efficiency, multilingual, and multimodal support, and better post-training techniques were used for instruction following and function calling, as well as additional data leading to substantial gains on key multimodal capabilities.
It is anticipated that Phi-4-multimodal-instruct will greatly benefit app developers and various use cases. The enthusiastic support for the Phi-4 series is greatly appreciated. Feedback on Phi-4 is welcomed and crucial to the model's evolution and improvement. Thank you for being part of this journey!
Model Quality
To understand the capabilities, Phi-4-multimodal-instruct was compared with a set of models over a variety of benchmarks using an internal benchmark platform (See Appendix A for benchmark methodology). Users can refer to the Phi-4-Mini-Instruct model card for details of language benchmarks. At the high-level overview of the model quality on representative speech and vision benchmarks:
Speech
The Phi-4-multimodal-instruct was observed as
- Having strong automatic speech recognition (ASR) and speech translation (ST) performance, surpassing expert ASR model WhisperV3 and ST models SeamlessM4T-v2-Large.
- Ranking number 1 on the Huggingface OpenASR leaderboard with word error rate 6.14% in comparison with the current best model 6.5% as of March 04, 2025.
- Being the first open-sourced model that can perform speech summarization, and the performance is close to GPT4o.
- Having a gap with close models, e.g. Gemini-1.5-Flash and GPT-4o-realtime-preview, on speech QA task. Work is being undertaken to improve this capability in the next iterations.
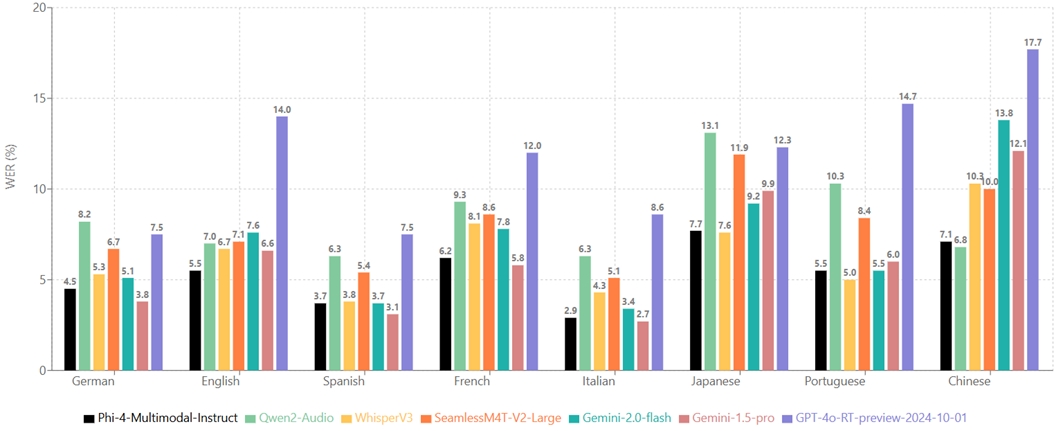
Speech Recognition (lower is better)
The performance of Phi-4-multimodal-instruct on the aggregated benchmark datasets:

The performance of Phi-4-multimodal-instruct on different languages, averaging the WERs of CommonVoice and FLEURS:
Speech Translation (higher is better)
Translating from German, Spanish, French, Italian, Japanese, Portugues, Chinese to English:

Translating from English to German, Spanish, French, Italian, Japanese, Portugues, Chinese. Noted that WhiperV3 does not support this capability:
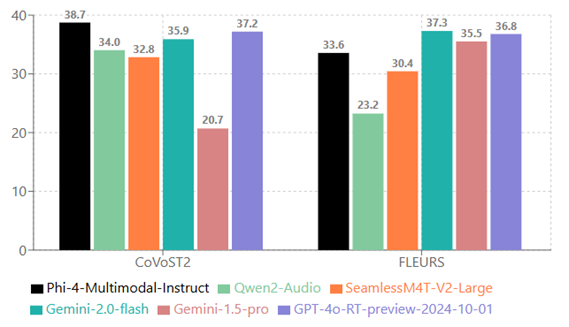
Speech Summarization (higher is better)

Speech QA
MT bench scores are scaled by 10x to match the score range of MMMLU:

Audio Understanding
AIR bench scores are scaled by 10x to match the score range of MMAU:

Vision
Vision-Speech tasks
Phi-4-multimodal-instruct is capable of processing both image and audio together, the following table shows the model quality when the input query for vision content is synthetic speech on chart/table understanding and document reasoning tasks. Compared to other existing state-of-the-art omni models that can enable audio and visual signal as input, Phi-4-multimodal-instruct achieves much stronger performance on multiple benchmarks.
Table with columns: Benchmarks, Phi-4-multimodal-instruct, InternOmni-7B, Gemini-2.0-Flash-Lite-prv-02-05, Gemini-2.0-Flash, Gemini-1.5-Pro| Benchmarks | Phi-4-multimodal-instruct | InternOmni-7B | Gemini-2.0-Flash-Lite-prv-02-05 | Gemini-2.0-Flash | Gemini-1.5-Pro |
|---|
| s_AI2D | 68.9 | 53.9 | 62.0 | 69.4 | 67.7 |
| s_ChartQA | 69.0 | 56.1 | 35.5 | 51.3 | 46.9 |
| s_DocVQA |
Vision tasks
To understand the vision capabilities, Phi-4-multimodal-instruct was compared with a set of models over a variety of zero-shot benchmarks using an internal benchmark platform. At the high-level overview of the model quality on representative benchmarks:
Table with columns: Dataset, Phi-4-multimodal-ins, Phi-3.5-vision-ins, Qwen 2.5-VL-3B-ins, Intern VL 2.5-4B, Qwen 2.5-VL-7B-ins, Intern VL 2.5-8B, Gemini 2.0-Flash Lite-preview-0205, Gemini2.0-Flash, Claude-3.5-Sonnet-2024-10-22, Gpt-4o-2024-11-20| Dataset | Phi-4-multimodal-ins | Phi-3.5-vision-ins | Qwen 2.5-VL-3B-ins | Intern VL 2.5-4B | Qwen 2.5-VL-7B-ins | Intern VL 2.5-8B | Gemini 2.0-Flash Lite-preview-0205 | Gemini2.0-Flash | Claude-3.5-Sonnet-2024-10-22 | Gpt-4o-2024-11-20 |
|---|
| Popular aggregated benchmark | | | | | | |

Visual Perception
Below are the comparison results on existing multi-image tasks. On average, Phi-4-multimodal-instruct outperforms competitor models of the same size and competitive with much bigger models on multi-frame capabilities.
BLINK is an aggregated benchmark with 14 visual tasks that humans can solve very quickly but are still hard for current multimodal LLMs.
Table with columns: Dataset, Phi-4-multimodal-instruct, Qwen2.5-VL-3B-Instruct, InternVL 2.5-4B, Qwen2.5-VL-7B-Instruct, InternVL 2.5-8B, Gemini-2.0-Flash-Lite-prv-02-05, Gemini-2.0-Flash, Claude-3.5-Sonnet-2024-10-22, Gpt-4o-2024-11-20| Dataset | Phi-4-multimodal-instruct | Qwen2.5-VL-3B-Instruct | InternVL 2.5-4B | Qwen2.5-VL-7B-Instruct | InternVL 2.5-8B | Gemini-2.0-Flash-Lite-prv-02-05 | Gemini-2.0-Flash | Claude-3.5-Sonnet-2024-10-22 | Gpt-4o-2024-11-20 |
|---|
| Art Style | 86.3 | 58.1 | 59.8 | 65.0 | 65.0 | 76.9 | 76.9 |

Usage
Requirements
Phi-4 family has been integrated in the 4.48.2 version of transformers. The current transformers version can be verified with: pip list | grep transformers.
We suggest to run with Python 3.10.
Examples of required packages:
flash_attn==2.7.4.post1
torch==2.6.0
transformers==4.48.2
accelerate==1.3.0
soundfile==0.13.1
pillow==11.1.0
scipy==1.15.2
torchvision==0.21.0
backoff==2.2.1
peft==0.13.2
Phi-4-multimodal-instruct is also available in Azure AI Studio
Tokenizer
Phi-4-multimodal-instruct supports a vocabulary size of up to 200064 tokens. The tokenizer files already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
Given the nature of the training data, the Phi-4-multimodal-instruct model is best suited for prompts using the chat format as follows:
Text chat format
This format is used for general conversation and instructions:
<|system|>You are a helpful assistant.<|end|><|user|>How to explain Internet for a medieval knight?<|end|><|assistant|>
This format is used when the user wants the model to provide function calls based on
the given tools. The user should provide the available tools in the system prompt,
wrapped by <|tool|> and <|/tool|> tokens. The tools should be specified in JSON format,
using a JSON dump structure. Example:
<|system|>You are a helpful assistant with some tools.<|tool|>[{"name": "get_weather_updates", "description": "Fetches weather updates for a given city using the RapidAPI Weather API.", "parameters": {"city": {"description": "The name of the city for which to retrieve weather information.", "type": "str", "default": "London"}}}]<|/tool|><|end|><|user|>What is the weather like in Paris today?<|end|><|assistant|>
This format is used for conversation with image:
<|user|><|image_1|>Describe the image in detail.<|end|><|assistant|>
For multiple images, the user needs to insert multiple image placeholders in the prompt as below:
<|user|><|image_1|><|image_2|><|image_3|>Summarize the content of the images.<|end|><|assistant|>
This format is used for various speech and audio tasks:
<|user|><|audio_1|>{task prompt}<|end|><|assistant|>
The task prompt can vary for different task.
Automatic Speech Recognition:
<|user|><|audio_1|>Transcribe the audio clip into text.<|end|><|assistant|>
Automatic Speech Translation:
<|user|><|audio_1|>Translate the audio to {lang}.<|end|><|assistant|>
Automatic Speech Translation with chain-of-thoughts:
<|user|><|audio_1|>Transcribe the audio to text, and then translate the audio to {lang}. Use <sep> as a separator between the original transcript and the translation.<|end|><|assistant|>
Spoken-query Question Answering:
<|user|><|audio_1|><|end|><|assistant|>
This format is used for conversation with image and audio.
The audio may contain query related to the image:
<|user|><|image_1|><|audio_1|><|end|><|assistant|>
For multiple images, the user needs to insert multiple image placeholders in the prompt as below:
<|user|><|image_1|><|image_2|><|image_3|><|audio_1|><|end|><|assistant|>
Vision
- Any common RGB/gray image format (e.g., (".jpg", ".jpeg", ".png", ".ppm", ".bmp", ".pgm", ".tif", ".tiff", ".webp")) can be supported.
- Resolution depends on the GPU memory size. Higher resolution and more images will produce more tokens, thus using more GPU memory. During training, 64 crops can be supported.
If it is a square image, the resolution would be around (8448 by 8448). For multiple-images, at most 64 frames can be supported, but with more frames as input, the resolution of each frame needs to be reduced to fit in the memory.
Audio
- Any audio format that can be loaded by soundfile package should be supported.
- To keep the satisfactory performance, maximum audio length is suggested to be 40s. For summarization tasks, the maximum audio length is suggested to 30 mins.
Loading the model locally
After obtaining the Phi-4-multimodal-instruct model checkpoints, users can use this sample code for inference.
import requests
import torch
import os
import io
from PIL import Image
import soundfile as sf
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from urllib.request import urlopen
model_path = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2',
).cuda()
generation_config = GenerationConfig.from_pretrained(model_path)
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
print("\n--- IMAGE PROCESSING ---")
image_url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
print("\n--- AUDIO PROCESSING ---")
audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
speech_prompt = "Transcribe the audio to text, and then translate the audio to French. Use <sep> as a separator between the original transcript and the translation."
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
audio, samplerate = sf.read(io.BytesIO(urlopen(audio_url).read()))
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
More inference examples can be found here.
vLLM inference
User can start a server with this command
python -m vllm.entrypoints.openai.api_server --model 'microsoft/Phi-4-multimodal-instruct' --dtype auto --trust-remote-code --max-model-len 131072 --enable-lora --max-lora-rank 320 --lora-extra-vocab-size 0 --limit-mm-per-prompt audio=3,image=3 --max-loras 2 --lora-modules speech=<path to speech lora folder> vision=<path to vision lora folder>
The speech lora and vision lora folders are within the Phi-4-multimodal-instruct folder downloaded by vLLM, you can also use the following script to find thoses:
from huggingface_hub import snapshot_download
model_path = snapshot_download(repo_id="microsoft/Phi-4-multimodal-instruct")
speech_lora_path = model_path+"/speech-lora"
vision_lora_path = model_path+"/vision-lora"
Training
Fine-tuning
A basic example of supervised fine-tuning (SFT) for speech and vision is provided respectively.
An example on how to extend speech recognition to a new language.
Model
- Architecture: Phi-4-multimodal-instruct has 5.6B parameters and is a multimodal transformer model. The model has the pretrained Phi-4-Mini-Instruct as the backbone language model, and the advanced encoders and adapters of vision and speech.
- Inputs: Text, image, and audio. It is best suited for prompts using the chat format.
- Context length: 128K tokens
- GPUs: 512 A100-80G
- Training time: 28 days
- Training data: 5T tokens, 2.3M speech hours, and 1.1T image-text tokens
- Outputs: Generated text in response to the input
- Dates: Trained between December 2024 and January 2025
- Status: This is a static model trained on offline datasets with the cutoff date of June 2024 for publicly available data.
- Supported languages:
- Text: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian
- Vision: English
Training Datasets
Phi-4-multimodal-instruct's training data includes a wide variety of sources, totaling 5 trillion text tokens, and is a combination of
- publicly available documents filtered for quality, selected high-quality educational data, and code
- newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (e.g., science, daily activities, theory of mind, etc.)
- high quality human labeled data in chat format
- selected high-quality image-text interleave data
- synthetic and publicly available image, multi-image, and video data
- anonymized in-house speech-text pair data with strong/weak transcriptions
- selected high-quality publicly available and anonymized in-house speech data with task-specific supervisions
- selected synthetic speech data
- synthetic vision-speech data.
Focus was placed on the quality of data that could potentially improve the reasoning ability for the model, and the publicly available documents were filtered to contain a preferred level of knowledge. As an example, the result of a game in premier league on a particular day might be good training data for large foundation models, but such information was removed for the Phi-4-multimodal-instruct to leave more model capacity for reasoning for the model's small size. The data collection process involved sourcing information from publicly available documents, with a focus on filtering out undesirable documents and images. To safeguard privacy, image and text data sources were filtered to remove or scrub potentially personal data from the training data.
The decontamination process involved normalizing and tokenizing the dataset, then generating and comparing n-grams between the target dataset and benchmark datasets. Samples with matching n-grams above a threshold were flagged as contaminated and removed from the dataset. A detailed contamination report was generated, summarizing the matched text, matching ratio, and filtered results for further analysis.
Software
Hardware
Note that by default, the Phi-4-multimodal-instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
- NVIDIA A100
- NVIDIA A6000
- NVIDIA H100
If you want to run the model on:
- NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with _attn_implementation="eager"
Responsible AI Considerations
Like other language models, the Phi family of models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
- Quality of Service: The Phi models are trained primarily on English language content across text, speech, and visual inputs, with some additional multilingual coverage. Performance may vary significantly across different modalities and languages:
- Text: Languages other than English will experience reduced performance, with varying levels of degradation across different non-English languages. English language varieties with less representation in the training data may perform worse than standard American English.
- Speech: Speech recognition and processing shows similar language-based performance patterns, with optimal performance for standard American English accents and pronunciations. Other English accents, dialects, and non-English languages may experience lower recognition accuracy and response quality. Background noise, audio quality, and speaking speed can further impact performance.
- Vision: Visual processing capabilities may be influenced by cultural and geographical biases in the training data. The model may show reduced performance when analyzing images containing text in non-English languages or visual elements more commonly found in non-Western contexts. Image quality, lighting conditions, and composition can also affect processing accuracy.
- Multilingual performance and safety gaps: We believe it is important to make language models more widely available across different languages, but the Phi 4 models still exhibit challenges common across multilingual releases. As with any deployment of LLMs, developers will be better positioned to test for performance or safety gaps for their linguistic and cultural context and customize the model with additional fine-tuning and appropriate safeguards.
- Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups, cultural contexts, or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
Developers should apply responsible AI best practices, including mapping, measuring, and mitigating risks associated with their specific use case and cultural, linguistic context. Phi 4 family of models are general purpose models. As developers plan to deploy these models for specific use cases, they are encouraged to fine-tune the models for their use case and leverage the models as part of broader AI systems with language-specific safeguards in place. Important areas for consideration include:
- Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
- High-Risk Scenarios: Developers should assess the suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
- Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
- Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
- Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
Safety
The Phi-4 family of models has adopted a robust safety post-training approach. This approach leverages a variety of both open-source and in-house generated datasets. The overall technique employed for safety alignment is a combination of SFT (Supervised Fine-Tuning), DPO (Direct Preference Optimization), and RLHF (Reinforcement Learning from Human Feedback) approaches by utilizing human-labeled and synthetic English-language datasets, including publicly available datasets focusing on helpfulness and harmlessness, as well as various questions and answers targeted to multiple safety categories. For non-English languages, existing datasets were extended via machine translation. Speech Safety datasets were generated by running Text Safety datasets through Azure TTS (Text-To-Speech) Service, for both English and non-English languages. Vision (text & images) Safety datasets were created to cover harm categories identified both in public and internal multi-modal RAI datasets.
Safety Evaluation and Red-Teaming
Various evaluation techniques including red teaming, adversarial conversation simulations, and multilingual safety evaluation benchmark datasets were leveraged to evaluate Phi-4 models' propensity to produce undesirable outputs across multiple languages and risk categories. Several approaches were used to compensate for the limitations of one approach alone. Findings across the various evaluation methods indicate that safety post-training that was done as detailed in the Phi 3 Safety Post-Training paper had a positive impact across multiple languages and risk categories as observed by refusal rates (refusal to output undesirable outputs) and robustness to jailbreak techniques. Details on prior red team evaluations across Phi models can be found in the Phi 3 Safety Post-Training paper. For this release, the red teaming effort focused on the newest Audio input modality and on the following safety areas: harmful content, self-injury risks, and exploits. The model was found to be more susceptible to providing undesirable outputs when attacked with context manipulation or persuasive techniques. These findings applied to all languages, with the persuasive techniques mostly affecting French and Italian. This highlights the need for industry-wide investment in the development of high-quality safety evaluation datasets across multiple languages, including low resource languages, and risk areas that account for cultural nuances where those languages are spoken.
Vision Safety Evaluation
To assess model safety in scenarios involving both text and images, Microsoft's Azure AI Evaluation SDK was utilized. This tool facilitates the simulation of single-turn conversations with the target model by providing prompt text and images designed to incite harmful responses. The target model's responses are subsequently evaluated by a capable model across multiple harm categories, including violence, sexual content, self-harm, hateful and unfair content, with each response scored based on the severity of the harm identified. The evaluation results were compared with those of Phi-3.5-Vision and open-source models of comparable size. In addition, we ran both an internal and the public RTVLM and VLGuard multi-modal (text & vision) RAI benchmarks, once again comparing scores with Phi-3.5-Vision and open-source models of comparable size. However, the model may be susceptible to language-specific attack prompts and cultural context.
Audio Safety Evaluation
In addition to extensive red teaming, the Safety of the model was assessed through three distinct evaluations. First, as performed with Text and Vision inputs, Microsoft's Azure AI Evaluation SDK was leveraged to detect the presence of harmful content in the model's responses to Speech prompts. Second, Microsoft's Speech Fairness evaluation was run to verify that Speech-To-Text transcription worked well across a variety of demographics. Third, we proposed and evaluated a mitigation approach via a system message to help prevent the model from inferring sensitive attributes (such as gender, sexual orientation, profession, medical condition, etc...) from the voice of a user.
License
The model is licensed under the MIT license.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
Appendix A: Benchmark Methodology
We include a brief word on methodology here - and in particular, how we think about optimizing prompts.
In an ideal world, we would never change any prompts in our benchmarks to ensure it is always an apples-to-apples comparison when comparing different models. Indeed, this is our default approach, and is the case in the vast majority of models we have run to date.
There are, however, some exceptions to this. In some cases, we see a model that performs worse than expected on a given eval due to a failure to respect the output format. For example:
- A model may refuse to answer questions (for no apparent reason), or in coding tasks models may prefix their response with “Sure, I can help with that. …” which may break the parser. In such cases, we have opted to try different system messages (e.g. “You must always respond to a question” or “Get to the point!”).
- Some models, we observed that few shots actually hurt model performance. In this case we did allow running the benchmarks with 0-shots for all cases.
- We have tools to convert between chat and completions APIs. When converting a chat prompt to a completion prompt, some models have different keywords e.g. Human vs User. In these cases, we do allow for model-specific mappings for chat to completion prompts.
However, we do not:
- Pick different few-shot examples. Few shots will always be the same when comparing different models.
- Change prompt format: e.g. if it is an A/B/C/D multiple choice, we do not tweak this to 1/2/3/4 multiple choice.
Vision Benchmark Settings
The goal of the benchmark setup is to measure the performance of the LMM when a regular user utilizes these models for a task involving visual input. To this end, we selected 9 popular and publicly available single-frame datasets and 3 multi-frame benchmarks that cover a wide range of challenging topics and tasks (e.g., mathematics, OCR tasks, charts-and-plots understanding, etc.) as well as a set of high-quality models.
Our benchmarking setup utilizes zero-shot prompts and all the prompt content are the same for every model. We only formatted the prompt content to satisfy the model's prompt API. This ensures that our evaluation is fair across the set of models we tested. Many benchmarks necessitate models to choose their responses from a presented list of options. Therefore, we've included a directive in the prompt's conclusion, guiding all models to pick the option letter that corresponds to the answer they deem correct.
In terms of the visual input, we use the images from the benchmarks as they come from the original datasets. We converted these images to base-64 using a JPEG encoding for models that require this format (e.g., GPTV, Claude Sonnet 3.5, Gemini 1.5 Pro/Flash). For other models (e.g., Llava Interleave, and InternVL2 4B and 8B), we used their Huggingface interface and passed in PIL images or a JPEG image stored locally. We did not scale or pre-process images in any other way.
Lastly, we used the same code to extract answers and evaluate them using the same code for every considered model. This ensures that we are fair in assessing the quality of their answers.
Speech Benchmark Settings
The objective of this benchmarking setup is to assess the performance of models in speech and audio understanding tasks as utilized by regular users. To accomplish this, we selected several state-of-the-art open-sourced and closed-sourced models and performed evaluations across a variety of public and in-house benchmarks. These benchmarks encompass diverse and challenging topics, including Automatic Speech Recognition (ASR), Automatic Speech Translation (AST), Spoken Query Question Answering (SQQA), Audio Understanding (AU), and Speech Summarization.
The results are derived from evaluations conducted on identical test data without any further clarifications. All results were obtained without sampling during inference. For an accurate comparison, we employed consistent prompts for models across different tasks, except for certain model APIs (e.g., GPT-4o), which may refuse to respond to specific prompts for some tasks.
In conclusion, we used uniform code to extract answers and evaluate them for all considered models. This approach ensured fairness by assessing the quality of their responses.
Benchmark datasets
The model was evaluated across a breadth of public and internal benchmarks to understand it's capabilities under multiple tasks and conditions. While most evaluations use English, multilingual benchmark was incorporated to cover performance in select languages. More specifically,
-
Vision:
- Popular aggregated benchmark:
- MMMU and MMMU-Pro: massive multi-discipline tasks at college-level subject knowledge and deliberate reasoning.
- MMBench: large-scale benchmark to evaluate perception and reasoning capabilities.
- Visual reasoning:
- ScienceQA: multimodal visual question answering on science.
- MathVista: visual math reasoning.
- InterGPS: Visual 2D geometry reasoning.
- Chart reasoning:
- ChartQA: visual and logical reasoning on charts.
- AI2D: diagram understanding.
- Document Intelligence:
Appendix B: Fine-tuning Korean speech
Overview and Datasets
Phi-4-multimodal is originally not designed for Korean speech-to-text task, but it can be fine-tuned for Korean speech-to-text task using your own data or public Korean speech datasets.
We have fine-tuned Phi-4-multimodal model for Korean speech-to-text task using the following datasets:
- kresnik/zeroth_korean
- mozilla-foundation/common_voice_17_0 (Used Korean speech only)
- PolyAI/minds14 (Used Korean speech only)
- Custom dataset. The speech was a mix of fast and slow speech (Technical blog contents and presentations that the author have posted), with some modulation using audiomentations and this script
Total 35K samples. Each sample is a pair of Korean speech and its transcription. Dataset was sampled 16kHz.
You can download the fine-tuned model here. Please refer to the Jupyter notebook and video clips in the demo folder. They are not production-quality as they were simply fine-tuned for PoC purposes, but you can see that they transcribe and translate with high accuracy even when a native speaker speaks quite quickly.
Requirements
Based on Python 3.10, the following packages are required, and A100/H100 GPU is recommended.
torch==2.6.0
transformers==4.48.2
accelerate==1.4.0
soundfile==0.13.1
pillow==11.1.0
scipy==1.15.2
torchvision==0.21.0
backoff==2.2.1
peft==0.14.0
datasets==3.3.2
pandas==2.2.3
flash_attn==2.7.4.post1
evaluate==0.4.3
sacrebleu==2.5.1
Training
The model was trained on a single A100 80GB GPU for 4 epochs with a batch size of 16 using the sample_finetune_speech.py script from microsoft/Phi-4-multimodal-instruct
The fine tuning script and command line are basically the same as here, but you need to prepare your own dataset. Also, to perform audio encoder unfreeze, please refer to the code snippet below. The code snippet is retrieved from the fine-tuning Colab notebook.
with accelerator.local_main_process_first():
processor = AutoProcessor.from_pretrained(
"microsoft/Phi-4-multimodal-instruct",
trust_remote_code=True,
)
model = create_model(
args.model_name_or_path,
use_flash_attention=args.use_flash_attention,
)
def unfreeze_speech_components(model):
"""Directly target verified components from your debug logs"""
audio_embed = model.model.embed_tokens_extend.audio_embed
audio_encoder = audio_embed.encoder
audio_projection = audio_embed.audio_projection
for component in [audio_embed, audio_encoder, audio_projection]:
for param in component.parameters():
param.requires_grad = True
return model
model = unfreeze_speech_components(model)
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Trainable parameters: {trainable_params:,}")
encoder_params = list(model.model.embed_tokens_extend.audio_embed.encoder.parameters())
proj_params = list(model.model.embed_tokens_extend.audio_embed.audio_projection.parameters())
assert any(p.requires_grad for p in encoder_params), "Encoder params frozen!"
assert any(p.requires_grad for p in proj_params), "Projection params frozen!"
print("Components properly unfrozen ✅")
Example commands to run finetuning scripts are as follows:
The latest version of the model currently uploaded was fine-tuned by unfreezing the audio encoder, and the ASR performance was significantly improved compared to the baseline LoRA adapter-based fine-tuning.
Comparing the full fine-tuning and LoRA fine-tuning, the CER on zeroth-test set is 1.61% and 2.72%, and the WER on zeroth-test set is 3.54% and 7.19%, respectively. Please refer to the Experimental Settings and Results for more details.
Experimental Settings and Results
The purpose of this benchmarking setup is to evaluate the basic performance of Korean audio in speech and audio understanding tasks. We did this for automatic speech recognition and automatic speech translation, and the test data used the following datasets and samples:
Evaluation was done on the following datasets:
Evaluation Script is retrieved from here
We used the Phi-4-mm-inst-zeroth-kor as a baseline to improve performance, as it showed significant performance improvement with 1 epoch. Note that the baseline was trained with 22K Zeroth Korean Korean speech data for 1 epoch. Based on this baseline with 35K training samples, we conducted additional experiments with the following scenarios:
- [Case 1] LoRA finetune (1 epoch): LoRA adapter-based fine-tuning for 1 epochs
- [Case 2] LoRA finetune (4 epochs): LoRA adapter-based fine-tuning for 4 epochs
- [Case 3] Unfreeze audio encoder finetune (4 epochs): Full fine-tuning for 4 epochs.
The results of the experiments are as follows:
Table with columns: Model, zeroth (CER), zeroth (WER), fleurs-ko2en, fleurs-ko2en-cot, fleurs-en2ko, fleurs-en2ko-cot| Model | zeroth (CER) | zeroth (WER) | fleurs-ko2en | fleurs-ko2en-cot | fleurs-en2ko | fleurs-en2ko-cot |
|---|
| original | 99.16 | 99.63 | 5.63 | 2.42 | 6.86 | 4.17 |
| Ours - speech full finetune (4 epochs) | 1.61 | 3.54 | 7.67 | 8.38 | 12.31 |
Cautions
Note that this model is just a PoC/experimental purpose, and not intended to be used in production. More high-quality data, tuning, ablation studies, and experiments are needed.
Phi-4-multimodal model is strong in multimodal tasks, especially in speech-to-text and high potential in Korean language tasks. Thus if you are interested in Korean speech-to-text task, this model can be a good starting point.
References
Data Summary
https://huggingface.co/microsoft/Phi-4-multimodal-instruct/blob/main/data_summary_card.md