Friendli InferenceThe fastest LLM inference engine
on the market
What Friendli Inference offers
Speed up the serving of LLMs,
thus slashing costs by50–90%
Friendli Inference is highly optimized to make LLM serving fast and cost-effective. Process LLM inference with Friendli Inference, the fastest engine on the market. Our performance testing shows that Friendli Inference is significantly faster than vLLM and TensorRT-LLM.

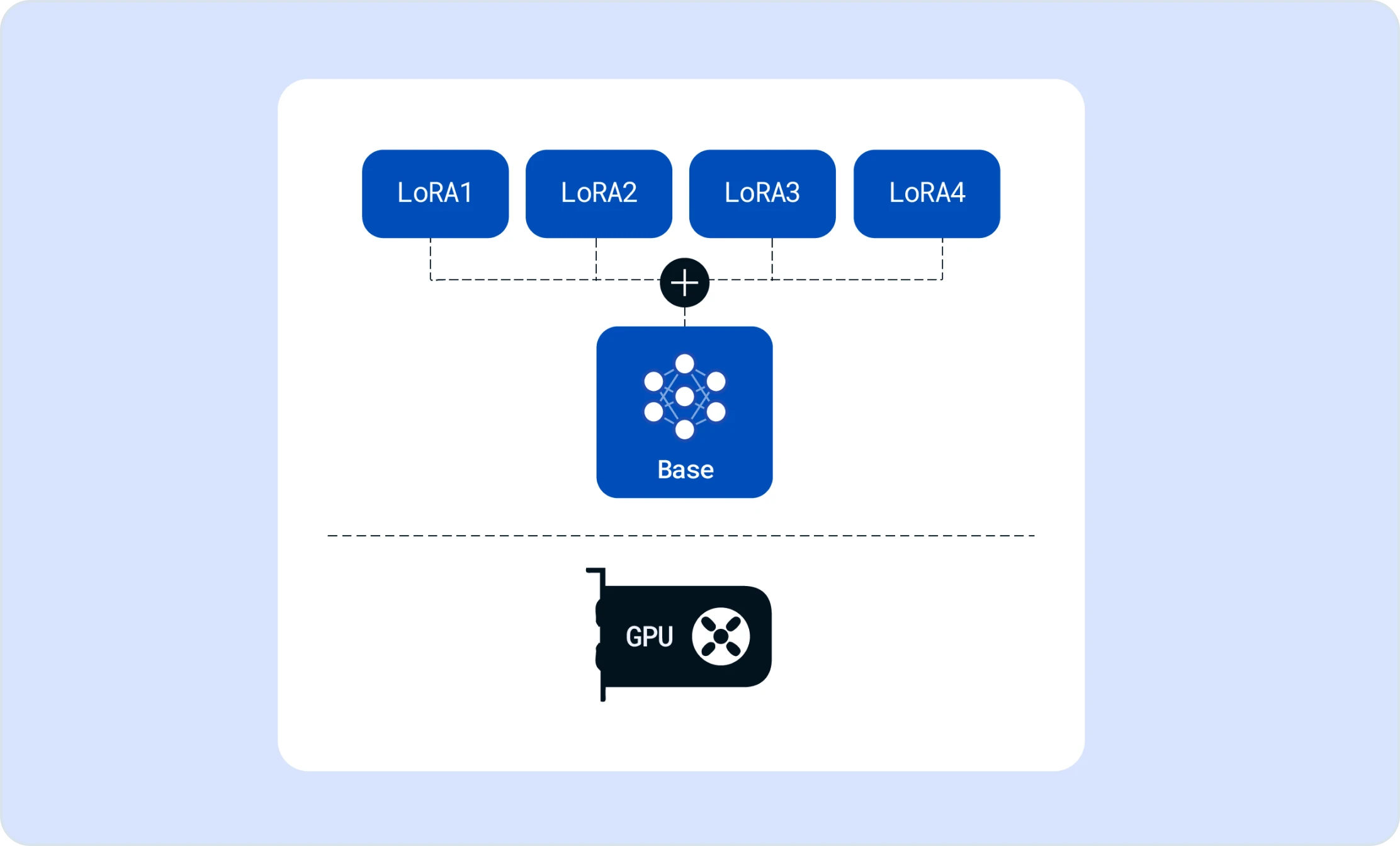
Multi-LoRA serving on a single GPU
Friendli Inference simultaneously supports multiple LoRA models on fewer GPUs (even on just a single GPU!), a remarkable leap in making LLM customization more accessible and efficient.
Deploy LLMs and more!
Friendli Inference supports a wide range of generative AI models, including quantized models and MoE.

Key Technology
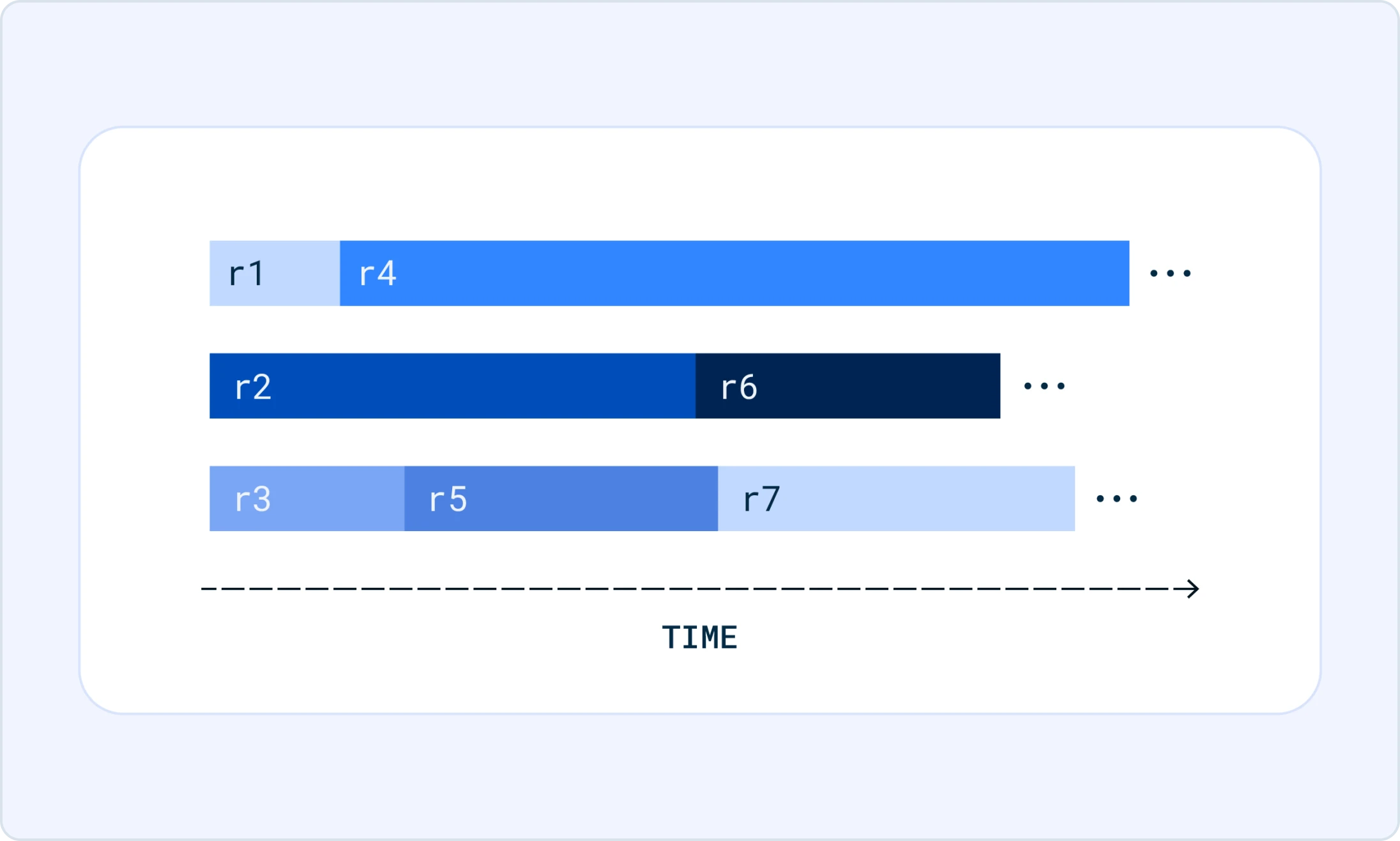
Iteration batching
(aka continuous batching)
Iteration batching is a new batching technology we invented to handle concurrent generation requests very efficiently. Iteration batching can achieve up to tens of times higher LLM inference throughput than conventional batching while satisfying the same latency requirement. Our technology is protected by our patents in the US, Korea and China
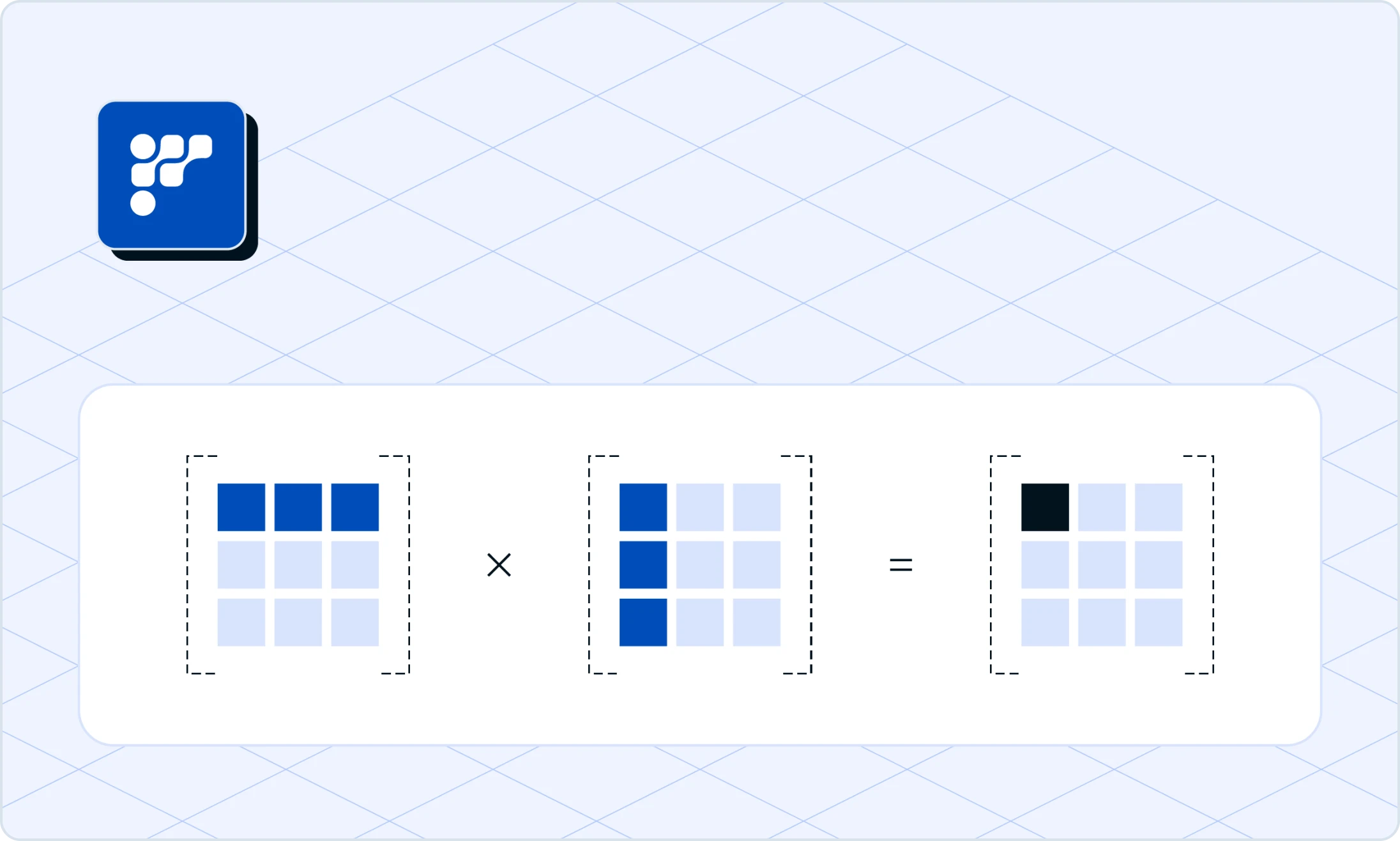
DNN library
Friendli DNN Library is the set of optimized GPU kernels carefully curated and designed specifically for generative AI. Our novel library allows Friendli Inference to support faster LLM inference of various tensor shapes and datatypes, as well as support quantization, Mixture of Experts, LoRA adapters, and so on.
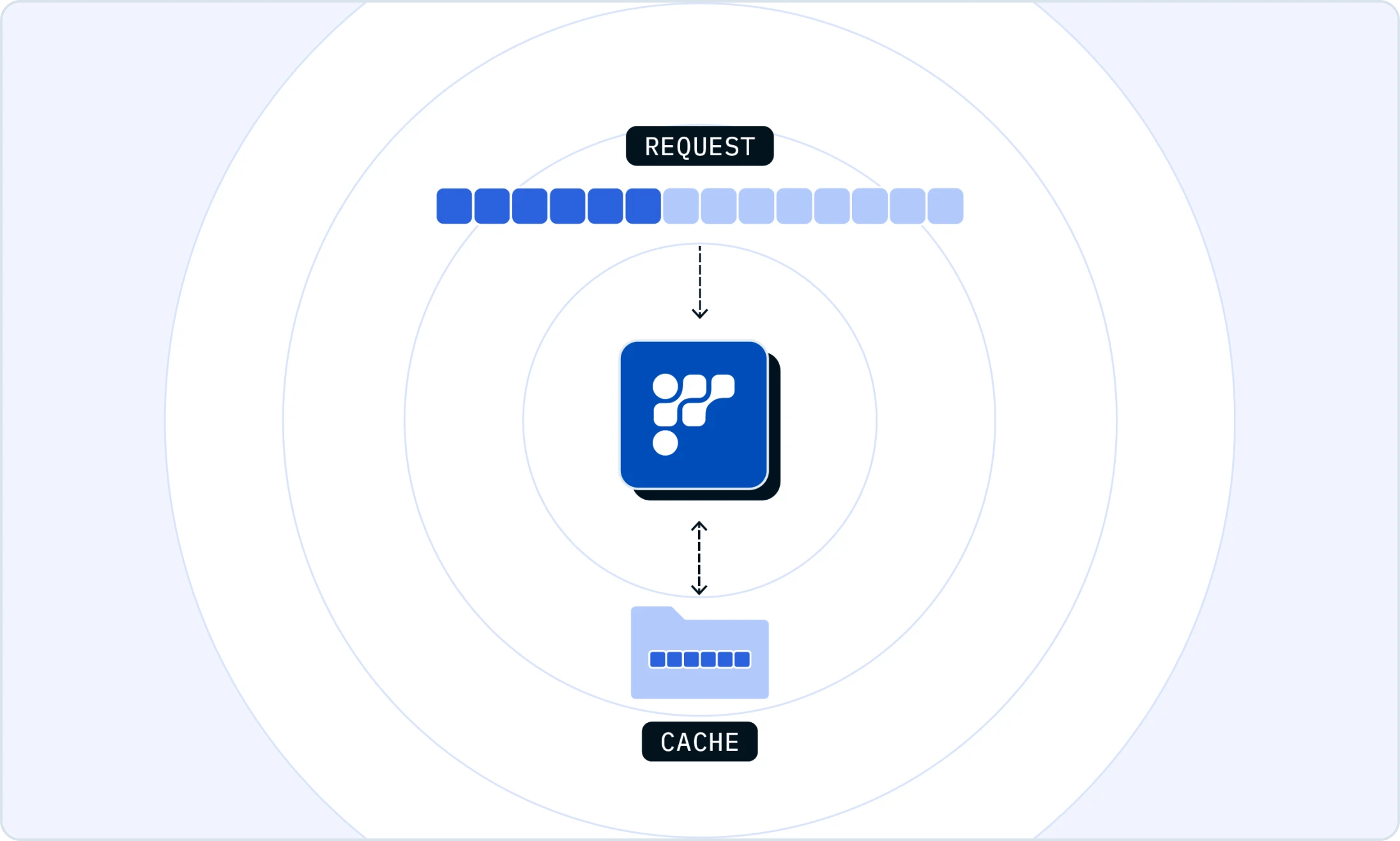
Friendli TCache
Friendli TCache intelligently identifies and stores frequently used computational results. The Friendli Inference leverages the cached results, significantly reducing the workload on the GPUs.
Speculative decoding
Friendli Inference natively supports speculative decoding, an optimization technique that rapidly speeds up LLM/LMM inference by making educated guesses on future tokens in parallel while generating the current token. Through validation of the generated potential future tokens, speculative decoding ensures identical model outputs at a fraction of the inference time.
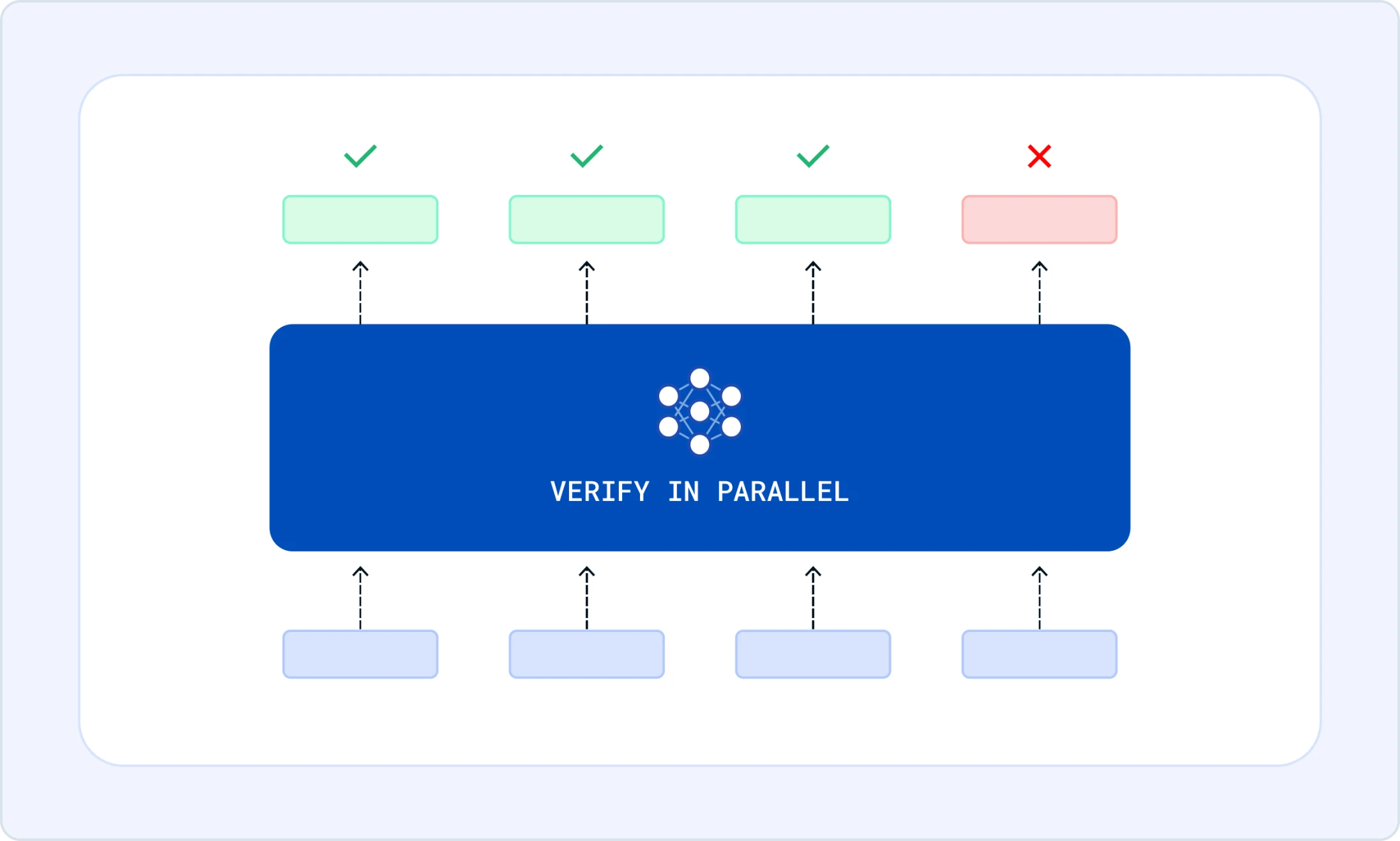
Highlights
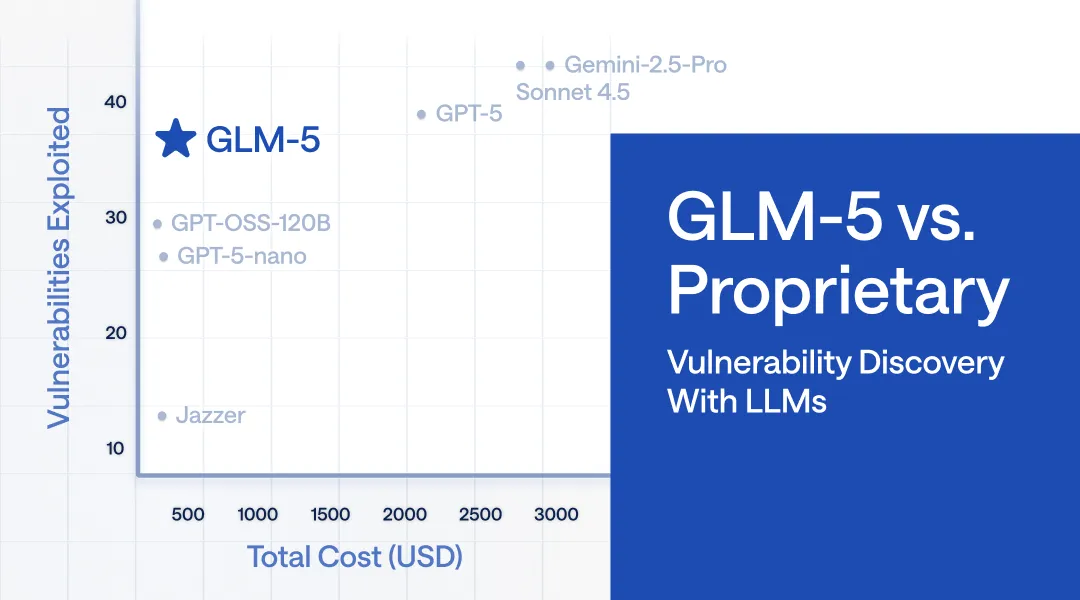
Vulnerability Discovery with Open-Weight GLM-5: Frontier Quality at 1/7 the Cost of Closed Models
In this post, we show how LLM-guided fuzzing dramatically improves vulnerability discovery. Through collaborations with leading security research groups, we demonstrate that open-weight models like GLM-5 running on FriendliAI can match closed-model results at roughly 1/7 of the cost.

Automating Industrial Inspection with Vision Language Models
Vision Language Models (VLMs) are revolutionizing industrial inspection by bridging the gap between rigid, high-speed deep learning models and flexible human reasoning.

Your Coding Agent is Only as Fast as Your Model API
Coding agents are becoming an essential part of modern development workflows. Tools such as Claude Code, Kilo Code, and OpenCode can read large repositories, generate patches, run tests, and iterate through multiple reasoning steps.
Three ways to run generative AI models with Friendli Inference:
03
Container
Serve LLM and LMM inferences with Friendli Inference in your private environment
Learn more