Run this model inference on single tenant GPU with unmatched speed and reliability at scale.
Run this model inference with full control and performance in your environment.
Get help setting up a custom Dedicated Endpoints.
Talk with our engineer to get a quote for reserved GPU instances with discounts.
README
License: apache-2.0Results (proof-of-concept)
Quality — Screen2Words test split (16 screens), ROUGE-L / BLEU vs human refs:
| model | ROUGE-L | BLEU |
|---|---|---|
| distilled student | 0.178 | 0.019 |
| untrained baseline | 0.153 | 0.018 |
The distilled student beats the untrained 2B baseline on ROUGE-L (+16% rel.) after only a short PoC training run.
Efficiency — teacher (7B) vs student (2B); Apple M4 Pro, MLX, 4-bit, 128 tokens:
| model | params (B) | latency p50 (ms) | throughput (img/s) | peak mem (GB) |
|---|---|---|---|---|
| teacher (Qwen2-VL-7B) | 8.29 | 1538 | 0.63 | 5.8 |
| student (Qwen2-VL-2B) | 2.21 | 651 | 1.52 | 2.4 |
→ ~2.4× faster, ~2.4× less memory, 3.75× fewer parameters.
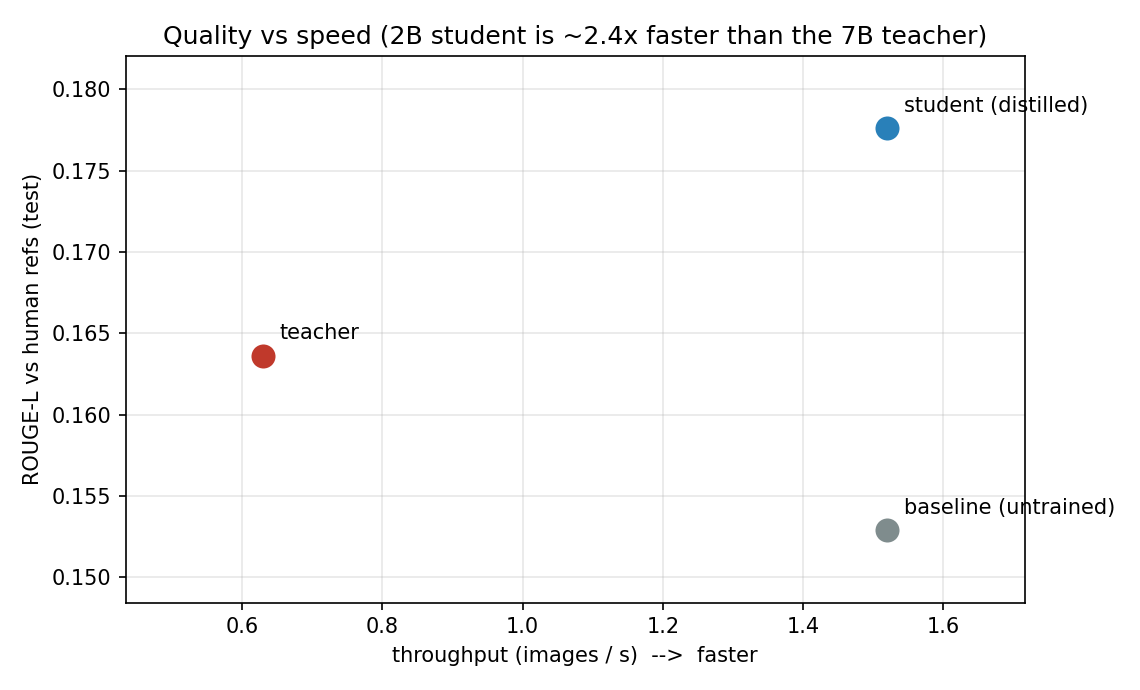
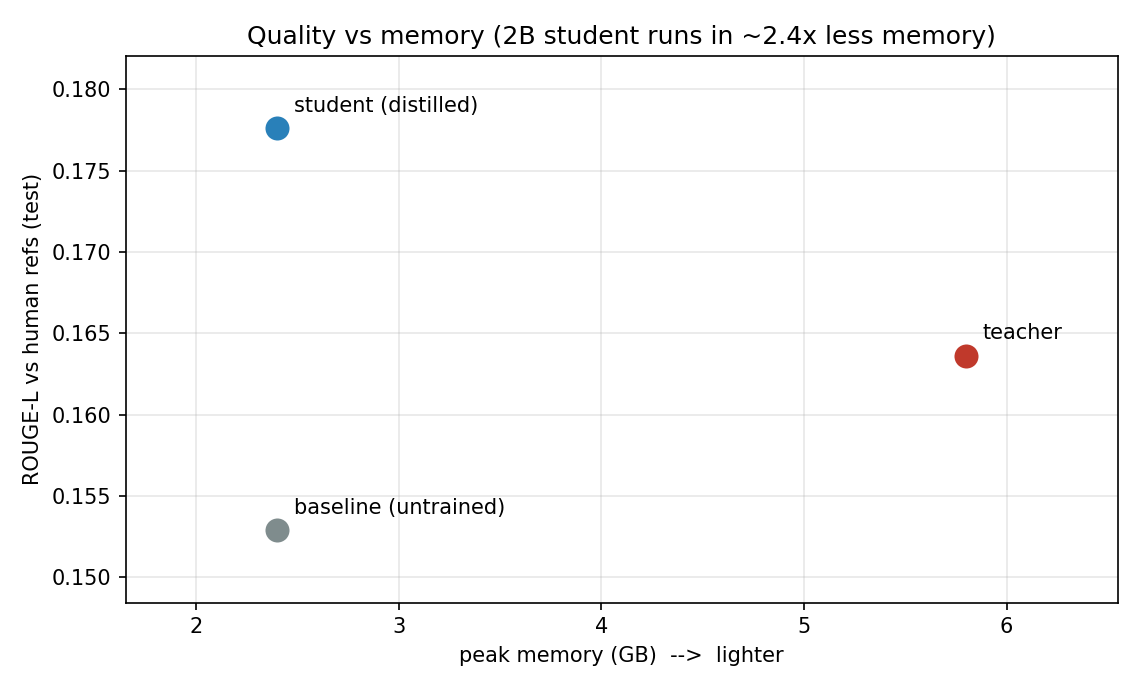
Note: against the short human references (median 7 words), ROUGE-L/BLEU undersell the verbose teacher — the 7B teacher actually scores lower on ROUGE-L (0.164) than the distilled student (0.178). LLM-as-judge / CIDEr would reward content over brevity-matching; the unambiguous win here is efficiency.
Usage
python
import torchfrom peft import PeftModelfrom PIL import Imagefrom transformers import AutoProcessor, Qwen2VLForConditionalGenerationBASE = "Qwen/Qwen2-VL-2B-Instruct"ADAPTER = "p00rt/qwen2-vl-2b-screenshots-distill"processor = AutoProcessor.from_pretrained(BASE, min_pixels=200704, max_pixels=401408)model = Qwen2VLForConditionalGeneration.from_pretrained(BASE, torch_dtype=torch.bfloat16)model = PeftModel.from_pretrained(model, ADAPTER).eval()image = Image.open("screenshot.png")prompt = ("Describe this UI screenshot in one sentence, then list the key ""interface elements as a comma-separated list.")messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt}]}]text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)inputs = processor(text=[text], images=[image], return_tensors="pt").to(model.device)out = model.generate(**inputs, max_new_tokens=128)print(processor.batch_decode(out[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0])
Training
- LoRA (r=16, α=32, dropout=0.05) on the language-model attention projections.
- Visual tokens capped (
max_pixels = 512·28·28) so large screenshots fit the context window. - Backend:
transformers+peft(hf), on CUDA or Apple MPS.
Limitations
- Narrow domain: Android UI screenshots (RICO). Not a general VLM.
- Perception only — no grounding (bounding boxes) and no action/agent layer.
- Inherits teacher biases and any teacher hallucinations in the distilled targets.
License & attribution
- Code & adapter: Apache-2.0.
- Base model
Qwen/Qwen2-VL-2B-Instruct: see the base model's license. - Screen2Words / RICO data: CC-BY-4.0.
Model provider
p00rt
Model tree
Base
Qwen/Qwen2-VL-2B-Instruct
Adapter
this model
Modalities
Input
Text, Image
Output
Text
Pricing
Dedicated Endpoints
View detailsSupported Functionality
Model APIs
Dedicated Endpoints
Container
More information