Model Overview
- Architecture: Whisper Large v3 Turbo (4 decoder layers vs 32 in standard Large v3)
- Language: Thai
- Dataset: ~11,000 hours of normalized Thai speech (Gigaspeech2, CommonVoice, Internal Curated Public Media)
- Task: Automatic Speech Recognition (ASR)
- License: MIT (inherited from OpenAI Whisper)
Typhoon Whisper Turbo achieves competitive performance against large-scale offline models on Thai speech recognition tasks.
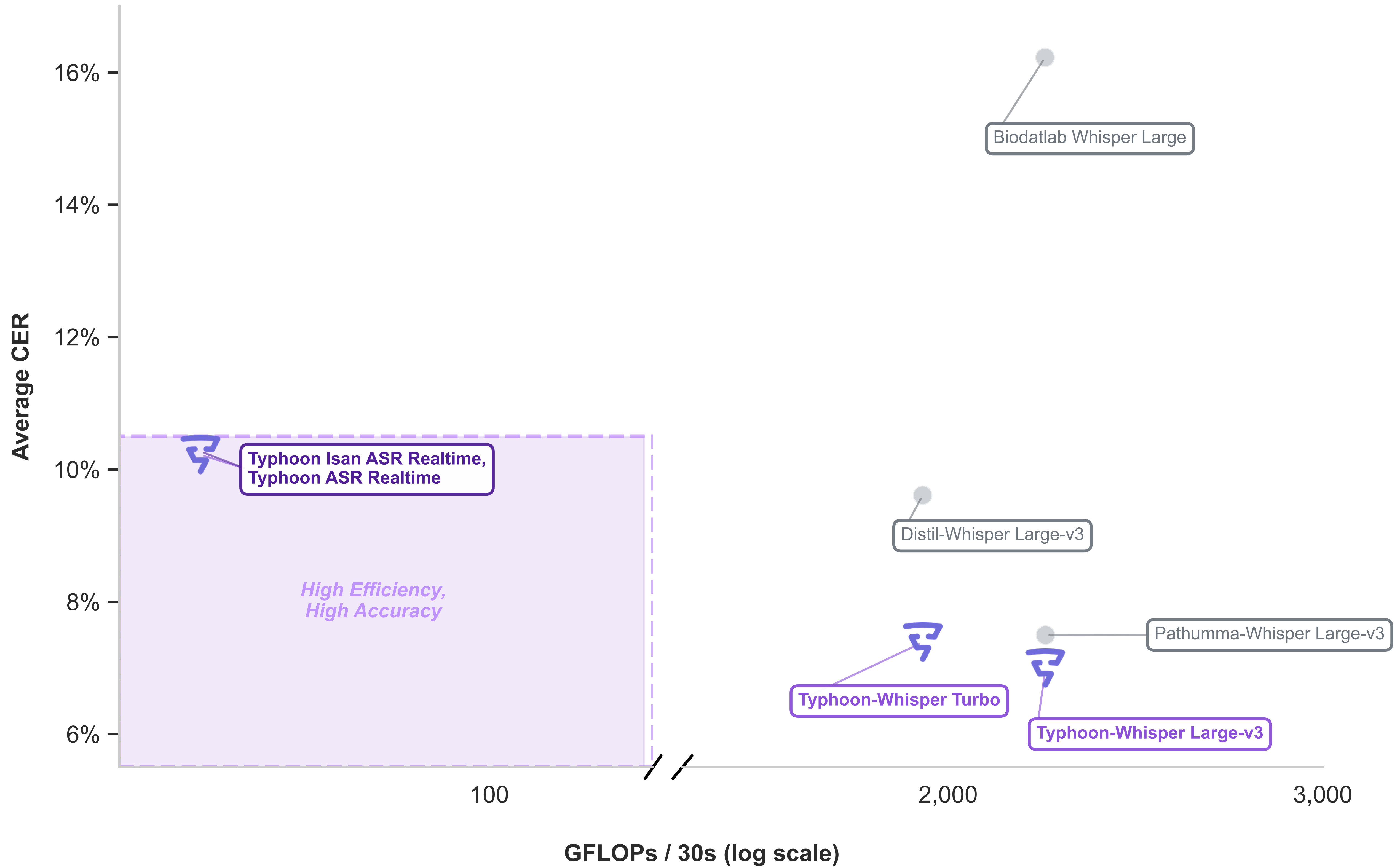
Note: Lower CER (Character Error Rate) is better. Results on Gigaspeech2 (Clean/Academic), TVSpeech (Noisy/In-the-wild), and Google Fleurs (Thai) testset.
Usage
You can use this model directly with the Hugging Face transformers library.
Installation
pip install transformers torch accelerate
Example Code
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
model_id = "scb10x/typhoon-whisper-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=448,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)
result = pipe("path_to_audio.wav", generate_kwargs={"language": "thai"})
print(result["text"])
Training Data
The model was trained on approximately 11,000 hours of Thai audio data, including:
- Gigaspeech2: Clean, academic-style speech
- CommonVoice: Crowd-sourced diverse speech samples
- Internal Curated Public Media: Proprietary datasets curated by Typhoon Team, SCB 10X
All data was normalized using the Typhoon data pipeline to ensure:
- Consistent handling of Thai numbers
- Proper treatment of repetition markers
- Resolution of context-dependent ambiguities
Model Architecture
Typhoon Whisper Turbo is based on OpenAI Whisper Large v3 Turbo, achieving performance comparable to state-of-the-art models while being significantly more efficient:
- Reduced model size: Only 4 decoder layers (compared to 32 in standard Large v3)
- Lower memory footprint: Requires substantially less GPU/CPU memory during inference
- Maintained accuracy: Competitive performance with minimal trade-off despite the compact architecture
Limitations
- The model is optimized specifically for Thai language speech recognition
- Performance may vary on dialects or accents not well-represented in the training data
- Best suited for offline transcription rather than real-time streaming applications
License
This model is released under the MIT License, inherited from OpenAI Whisper.
Citation
If you use this model in your research or application, please cite our technical report:

@misc{warit2026typhoonasrr,
title={Typhoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition},
author={Warit Sirichotedumrong and Adisai Na-Thalang and Potsawee Manakul and Pittawat Taveekitworachai and Sittipong Sripaisarnmongkol and Kunat Pipatanakul},
year={2026},
eprint={2601.13044},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.13044},
}
For questions or feedback, please visit our website or open an issue on the model's repository.
Developed by: Typhoon Team, SCB 10X
Model Card Version: 1.0
Last Updated: January 2026