- July 13, 2023
- 5 min read
Accelerating LLM Training with Memory-Balanced Pipeline Parallelism
We are delighted to announce that FriendliAI’s work has been accepted and selected for an oral presentation in ICML ‘23! FriendliAI is a leading expert in generative AI software, particularly renowned for its Friendli Engine system, which offers exceptional performance in serving large language models (LLMs). Today, we are happy to share our latest work in training LLMs.
Pipeline parallelism is an established technique for training LLMs. However, it often leads to memory imbalance, in which certain GPUs face high memory pressure whereas others remain underutilized. This imbalance results in suboptimal performance since the overall GPU memory capacity allows for a more efficient setup.
BPipe, our novel method of pipeline parallelism, effectively resolves the memory imbalance problem. During training, BPipe achieves a balanced memory load across pipeline stages by transferring activations between earlier and later stages. Our evaluations on GPT-3 models show that BPipe can train the same models 1.25 to 2.17 times faster than Megatron-LM [1] by executing more efficient training configurations. We present the details below.
Background: Pipeline Parallelism

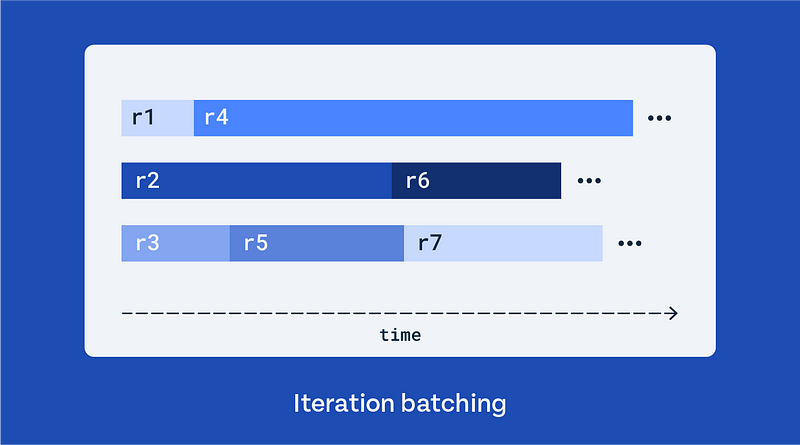
Under pipeline parallelism, GPUs align with specific pipeline stages, each responsible for a subset of the model's layers. Accordingly, data dependencies exist between pipeline stages, requiring the arrival of necessary data for either forward or backward computation. To prevent the GPUs from being idle, an input batch is divided into micro-batches and processed in a pipelined manner, as the above figure describes.
A single training step of pipeline parallelism is comprised of three distinct phases: warmup, steady, and cooldown. During the warmup phase, all pipeline stages compute a respective number of forward micro-batch(es). Since the intermediate activations required for backward computation need to be preserved, the memory usage of each pipeline stage increases. In the steady phase, forward and backward computations alternate within each pipeline stage. Memory usage remains constant as the saved activations are released after each backward computation. Finally, in the cooldown phase, memory usage decreases as the remaining backward computations are carried out.
Problem: Memory-Imbalance
However, the execution of the pipeline leads to a memory imbalance across pipeline stages. Specifically, each pipeline stage computes a different number of forward micro-batches in the warmup phase. For p-way pipeline parallelism, stage s computes p — s micro-batches in the warmup phase.

The graph shows the memory usage of each pipeline stage when training a GPT-3 13B model with 8-way pipeline parallelism, using eight NVIDIA A100 80 GiB GPUs. Here, the first stage computes eight micro-batches during the warmup phase. Consequently, the number of micro-batches in stages 0 and 7 differ by seven, resulting in a memory imbalance of 37 GiB. Attempting to utilize the unused memory might fail because the first stage no longer possesses enough memory.
Solution: Memory-Balanced Pipeline Parallelism
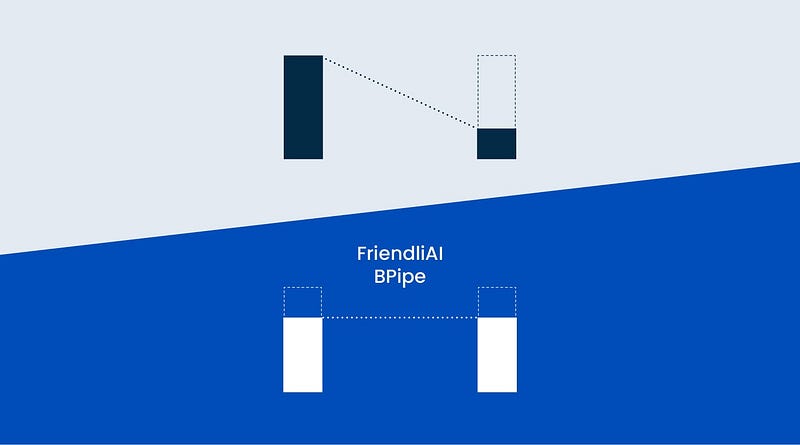
Our goal is to achieve balanced memory usage for all pipeline stages. To accomplish this, we pair up stages s and p — s — 1 for p-way pipeline parallelism. In each pair, the earlier stage becomes an evictor, and the later stage becomes an acceptor. For each training step, an evictor evicts the activations to its pair acceptor and loads before processing backward computation.

The above figure illustrates how BPipe operates within a single training step in 4-way pipeline parallelism. Stages 0 and 3 compose an evictor-acceptor pair. In the absence of BPipe, stage 0 holds a maximum of four micro-batches, while stage 3 holds only a single micro-batch. However, with BPipe, the two stages carry a similar number of micro-batches: three for stage 0 and two for stage 3.
Evaluation
We conducted evaluations on a cluster comprising six nodes, each equipped with eight NVIDIA 80 GiB A100 GPUs interconnected via NVLink and HDR InfiniBand. We compared BPipe against Megatron-LM, a state-of-the-art framework for LLM training. We selected two workloads, training a GPT-3 96B model with 32 A100 GPUs and GPT-3 134B model with 48 A100 GPUs.

The bar graph displays model FLOPS utilization (MFU), a ratio of the observed FLOPS to its theoretical maximum, for all feasible training configurations of BPipe and Megatron-LM. Each label of the bars represents the corresponding training configuration, which is further described in the paper. Notably, while Megatron-LM fails to execute certain configurations due to out-of-memory errors (indicated by a red ‘X’), BPipe succeeds by balancing the memory usage. As a result, BPipe achieves a 1.25x speedup over the fastest training configuration of Megatron-LM and a 2.17x speedup over the most inefficient configuration of Megatron-LM.

The graph presents the memory usage of each pipeline stage for the configuration where BPipe outperforms Megatron-LM, under the GPT-3 134B workload. Megatron-LM fails to execute the same configuration because of the high memory pressure of the first stage. Yet, BPipe alleviates it and facilitates execution by transferring activations.

To further underscore the value of BPipe, the preceding graph presents the MFU when applying FlashAttention2 [2] to BPipe. BPipe succeeds in utilizing FlashAttention with efficient memory utilization. As a result, it achieves 59% MFU, preserving the computation correctness. In contrast, Megatorn-LM fails to execute because of the memory imbalance, as previously mentioned.
Summary
Pipeline parallelism is essential for LLM training but entails memory imbalance. We came up with a novel pipeline parallelism method, memory-balanced pipeline parallelism. This technique transfers intermediate activations between earlier and later pipeline stages, achieving a more evenly distributed memory load. Our evaluation demonstrated that the balanced memory load facilitates the execution of efficient training configurations, while Megatron-LM fails.
The research on BPipe will be presented in ICML ‘23 on July 26th. You can get early access through this link.
For more information about FriendliAI, check this link.
[1] Korthikanti, Vijay Anand, et al. “Reducing activation recomputation in large transformer models.” Proceedings of Machine Learning and Systems 5 (2023).
[2] Dao, Tri. “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.” arXiv preprint arXiv:2307.08691 (2023).
Written by
FriendliAI Tech & Research
Share