Fine-tuning:Streamline from fine-tuning to serving
Optimize generative AI performance by customizing models
Achieve your business goals more effectively by fine-tuning pre-trained models with your enterprise's data, optimizing performance and saving both time and resources.
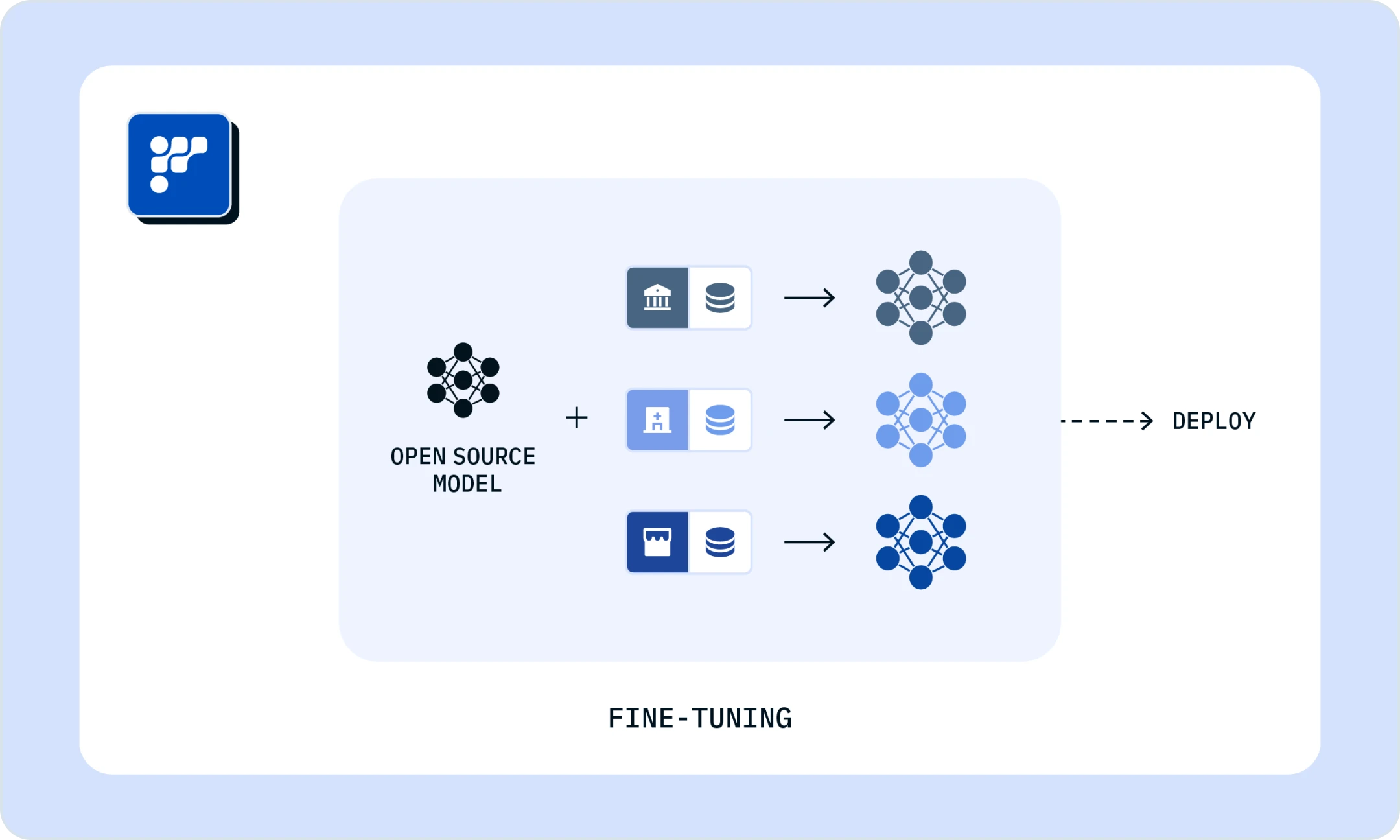
Fine-Tuning
Optimize pre-trained models with your enterprise data to achieve business specific goals.
Optimized multi GPU training
Parameter-Efficient
Fine-Tuning
Fine-tune models efficiently by updating only relevant parameters, preserving performance while saving computational resources, making it a top choice for model refinement.
Faster Training
Instead of updating all model parameters, this method focuses on updating only a subset of the pre-trained model's parameters. Fewer updates means less time and resources, saving costs.
Maintains Accuracy
Preserves pre-trained model's valuable knowledge for seamless adaptation to new tasks. Despite using fewer resources, parameter-efficient fine-tuning maintains accuracy levels.
Effortlessly deploy your fine tuned models
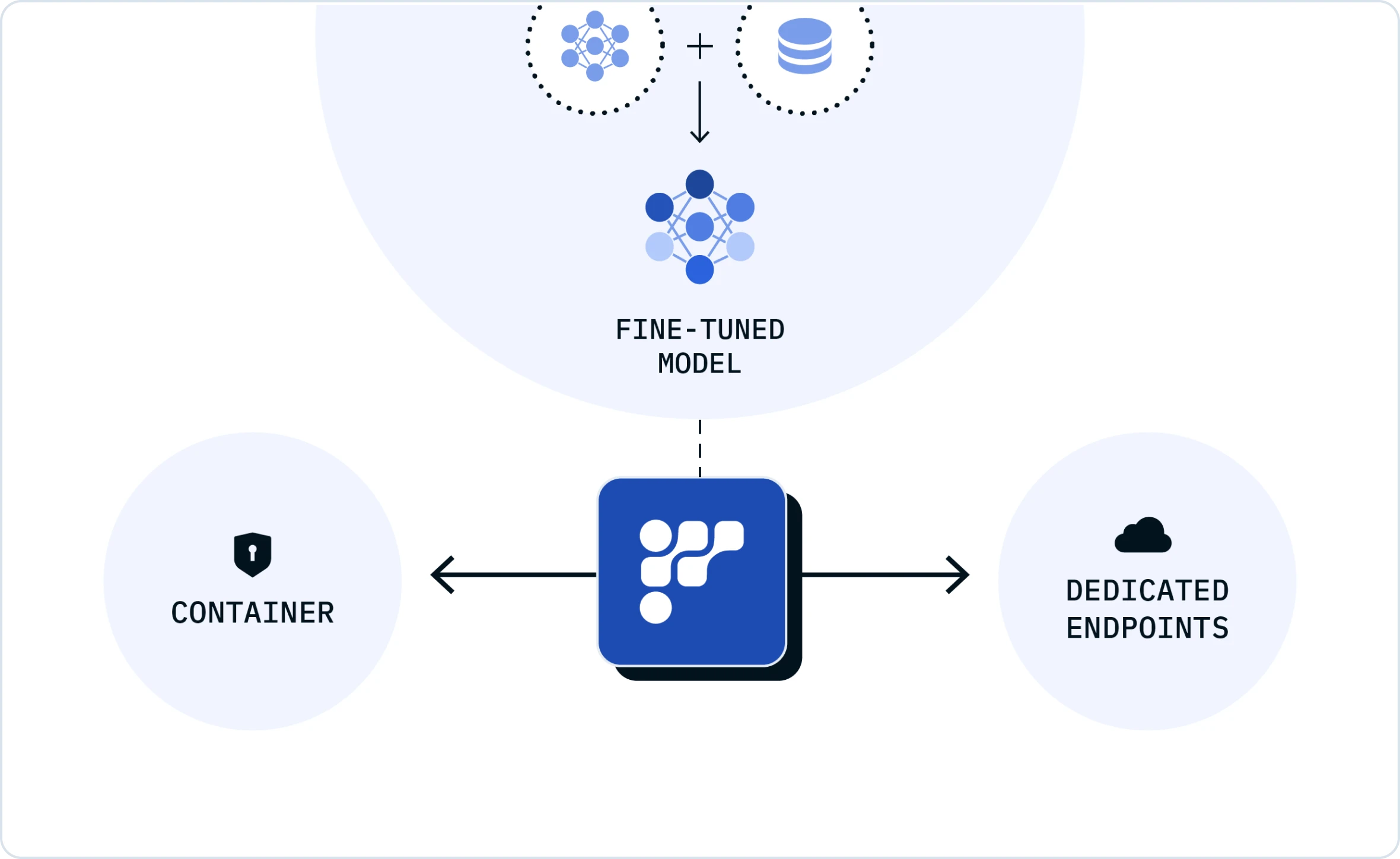
Friendli Suite not only enables you to easily fine-tune your models but also streamlines the deployment process. You can run your fine-tuned models in your GPU environment with Friendli Container or on Friendli dedicated endpoints with just a few clicks. This seamless process ensures high performance and cost-efficiency for your operations.
Fine-tune open-source LLMs
on Friendli Dedicated Endpoints
Try nowLLAMA 2 7B HF
LLAMA 2 13B HF
META LLAMA 3 8B
META LLAMA 3 8B INSTRUCT
Serve a fine-tuned model
in one-click with Friendli
01
Friendli Container
Serve LLMs/LMMs inferences with Friendli Engine in your GPU environment
Learn more02
Friendli Dedicated Endpoints
Build and run LLMs/LMMs on autopilot with Friendli Dedicated Endpoints
Learn more