- May 28, 2026
- 5 min read
Kimi K2.6 Meets FriendliAI: Frontier Agentic AI, Deployed in One Click
- Kimi K2.6 is Moonshot AI's open-weight Mixture-of-Experts model with 1T total parameters, 32B activated parameters, a 256K context window, and a MoonViT vision encoder.
- Built for long-horizon coding, agent swarms, multimodal reasoning, and proactive orchestration, Kimi K2.6 targets complex production workloads beyond short-form chat.
- Posts strong benchmarks: 80.2 SWE-Bench Verified, 89.6 LiveCodeBench v6, 96.4 AIME 2026, and 83.2 BrowseComp across agentic and coding tasks.
- Friendli Dedicated Endpoints support 1-click deployments for 560k+ open-weight or custom models via direct Hugging Face integration on dedicated GPU hardware.
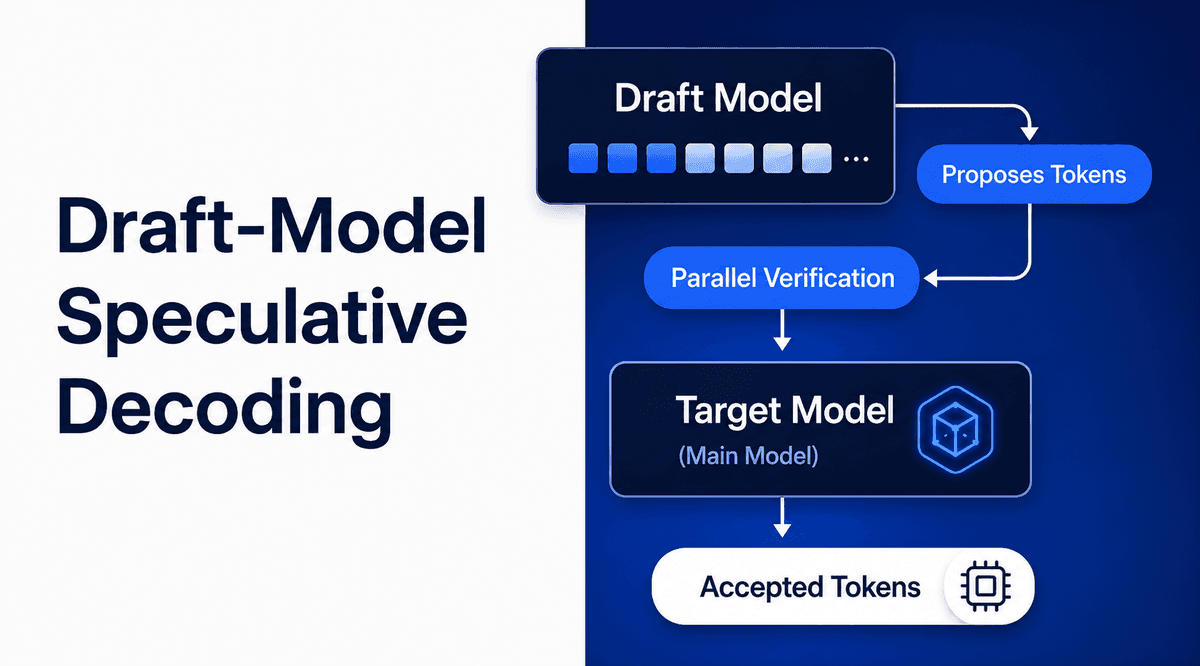
- Configure your deployment with the Friendli Engine, which includes custom kernels, host KV caching, online quantization, n-gram and draft-model speculative decoding, and routing.

Kimi K2.6 is built for the next phase of AI applications: not just chat, but autonomous coding, long-running agent workflows, multimodal understanding, and coordinated task execution. Developed by Moonshot AI, Kimi K2.6 is an open-source, native multimodal agentic model designed for long-horizon coding, coding-driven design, proactive autonomous execution, and swarm-based task orchestration.
For teams building production AI systems, the opportunity is clear: Kimi K2.6 combines strong open-weight model performance with the flexibility to run on your own dedicated infrastructure. With Friendli Dedicated Endpoints, teams can deploy open-source models like Kimi K2.6 on dedicated GPU hardware without managing infrastructure, sharing resources, or stitching together a custom serving stack.
Why Kimi K2.6 stands out
Kimi K2.6 is a Mixture-of-Experts model with 1T total parameters and 32B activated parameters, plus a 256K context window and a MoonViT vision encoder. That architecture makes it especially compelling for complex workloads where a model needs to reason over large amounts of context, use tools, interpret visual inputs, and execute multi-step tasks reliably.
Moonshot positions Kimi K2.6 around four major strengths: long-horizon coding, coding-driven design, elevated Agent Swarm, and proactive orchestration. The model card describes Kimi K2.6 as capable of handling complex coding tasks across Rust, Go, Python, front-end, DevOps, and performance optimization workflows; turning prompts and visual inputs into production-ready interfaces; and scaling horizontally to hundreds of sub-agents across thousands of coordinated steps.
In practical terms, this means Kimi K2.6 is not just another general-purpose model. It is built for builders: engineering teams, AI product teams, platform teams, and enterprises that want to turn open-weight AI into real applications.
Benchmark highlights
Kimi K2.6 posts strong results across agentic, coding, reasoning, and vision benchmarks. Moonshot reports a 54.0 score on HLE-Full with tools, 83.2 on BrowseComp, 92.5 F1 on DeepSearchQA, and 80.8 item-F1 on WideSearch.
For software engineering, the results are especially relevant. Kimi K2.6 scores 66.7 on Terminal-Bench 2.0, 58.6 on SWE-Bench Pro, 80.2 on SWE-Bench Verified, and 89.6 on LiveCodeBench v6. These are the kinds of benchmarks that matter when teams are evaluating models for coding agents, codebase maintenance, automated debugging, test generation, refactoring, and developer productivity tools.
The model also performs strongly on reasoning and multimodal tasks, including 96.4 on AIME 2026, 90.5 on GPQA-Diamond, 79.4 on MMMU-Pro, and 93.2 on MathVision with Python.
| Benchmark Results | |
|---|---|
| HLE-Full (with tools) | 54.0 |
| BrowseComp | 83.2 |
| DeepSearchQA (F1) | 92.5 |
| WideSearch (item-F1) | 80.8 |
| Terminal-Bench 2.0 | 66.7 |
| SWE-Bench Pro | 58.6 |
| SWE-Bench Verified | 80.2 |
| LiveCodeBench v6 | 89.6 |
| AIME 2026 | 96.4 |
| GPQA-Diamond | 90.5 |
| MMMU-Pro | 79.4 |
| MathVision (with Python) | 93.2 |
The takeaway: Kimi K2.6 is a high-capability open model for teams that need more than short-form chat. It is designed for longer workflows, deeper reasoning, and more sophisticated agentic systems.

Use cases for Kimi K2.6
Kimi K2.6 is well suited for applications where models need to work through complex tasks rather than simply answer one-off prompts.
For software engineering teams, Kimi K2.6 can power coding assistants, autonomous debugging tools, codebase migration agents, CI/CD copilots, and internal developer platforms. Its benchmark performance on SWE-Bench Pro, SWE-Bench Verified, Terminal-Bench 2.0, and LiveCodeBench makes it a strong candidate for real coding workflows.
For agentic AI builders, Kimi K2.6’s long-context and tool-use capabilities make it useful for research agents, workflow automation, multi-step analysis, and systems that need to coordinate across documents, websites, spreadsheets, code, and APIs. Moonshot describes Kimi K2.6 as supporting swarm-based orchestration and coordinated sub-agent execution.
For product and design teams, Kimi K2.6 can support coding-driven UI generation, front-end prototyping, and lightweight full-stack workflows. Moonshot describes the model as capable of transforming prompts and visual inputs into structured layouts, interactive elements, and production-ready interfaces.
For enterprise AI teams, Kimi K2.6’s open-weight availability under a Modified MIT License gives organizations more control over deployment, optimization, and model ownership than closed model APIs typically allow.
Why deploy Kimi K2.6 on Friendli Dedicated Endpoints?
A powerful model is only useful in production if it can be served reliably, efficiently, and at scale. That is where Friendli Dedicated Endpoints come in.
Friendli Dedicated Endpoints let teams run custom or open-source generative AI models on dedicated GPU hardware with no shared resources or infrastructure management. Teams can choose models from Hugging Face or Weights & Biases, select GPU resources, and receive an endpoint address for inference requests.
For Kimi K2.6, that means you can move from model discovery to production-oriented deployment much faster. Friendli Dedicated Endpoints support 1-click deployments for 560k+ open-weight or custom models available through direct integrations with Hugging Face.
Instead of assembling your own serving stack, configuring GPU infrastructure, tuning kernels, managing scaling behavior, and building monitoring from scratch, teams can deploy Kimi K2.6 on infrastructure purpose-built for high-performance inference.
One-click deployment, production-grade control
Friendli Dedicated Endpoints are designed to make deployment simple without removing the controls production teams need. The quickstart flow is straightforward: create a project, pick a model, deploy an endpoint, and generate your first inference response.
For teams deploying from Hugging Face, Friendli’s documentation walks through endpoint creation, model selection, instance selection, configuration, and deployment. The final deployment step is simply to click Deploy to create a new endpoint.
That simplicity matters. Kimi K2.6 is a large, capable model. Getting it into production should not require every team to become an inference infrastructure team. We handle the serving layer so builders can focus on the application layer.
Built for performance optimization
As usage grows, inference performance becomes a business problem, not just an infrastructure problem. Latency, throughput, GPU utilization, and cost per token all shape the user experience and the economics of an AI product.
Our approach is built around high-performance inference. Dedicated Endpoints are powered by the Friendli Engine, which automatically orchestrates resources for high-performance inference. Dedicated Endpoints also support custom kernels, host KV caching, online quantization, cache-aware routing, n-gram and draft-model speculative decoding.
For teams that want a deeper optimization path, The Friendli Guide to Inference Performance Optimization outlines a practical methodology for sizing infrastructure, benchmarking realistic workloads, tuning inference configurations, and selecting the optimal operating point across metrics like TTFT, TPOT, and system TPS.
That means teams can start quickly with one-click deployment, then work with our engineering team to tune Kimi K2.6 for specific workloads, whether the goal is lower latency, higher throughput, better GPU utilization, or stronger cost efficiency.
Get started with Kimi K2.6 on FriendliAI
Kimi K2.6 gives teams a powerful open model for coding, agents, long-context reasoning, multimodal inputs, and autonomous workflows. Friendli Dedicated Endpoints give teams a fast path to deploy that model on dedicated GPU infrastructure with the reliability, performance, and operational simplicity required for production AI.
Provision a Friendli Dedicated Endpoint for Kimi K2.6 today, or contact us to discuss the best deployment and optimization strategy for your workload. From one-click launch to performance tuning, we help teams turn frontier open models into production-ready AI systems.
Written by
FriendliAI Tech & Research
Share
General FAQ
What is FriendliAI?
FriendliAI is the Frontier Inference Cloud for Agents, delivering high throughput, low latency, and reliability at scale for agentic workloads. Through vertically optimized inference infrastructure, it delivers 2–5× faster output token speed and a 99.99% uptime SLA for high-volume production traffic.
How does FriendliAI reduce inference costs?
FriendliAI reduces inference costs through higher GPU utilization and optimized inference performance. FriendliAI's patented continuous batching technique, along with quantization, speculative decoding, KV cache offloading, multi-LoRA serving, and autoscaling, helps you serve more tokens with fewer GPUs, lowering your infrastructure costs without sacrificing performance.
Why should I choose FriendliAI over other inference providers?
FriendliAI is built for production AI agents, combining speed, reliability, and efficiency at scale. It delivers low-latency streaming, reliable long-context inference, and robust tool calling without compromising stability. According to independent OpenRouter benchmarks, FriendliAI consistently ranks among the top providers for throughput, latency, and reliability across leading open-weight models. See why customers choose FriendliAI
Which open-weight models does FriendliAI support?
Run today’s frontier open-weight models—including GLM, MiniMax, Kimi, DeepSeek, Qwen, Gemma, and more—with a simple API call. FriendliAI Model API gives you instant access to the latest models with optimized inference performance for production workloads. Explore models and pricing
How do I get started?
Getting started takes just a few minutes. [1] Sign up for FriendliAI, [2] Generate your API key, and [3] Make your first inference request with frontier open-weight models.
Still have questions?
If you want a customized solution for that key issue that is slowing your growth, support@friendli.ai or click Talk to an engineer — our engineers (not a bot) will reply within one business day.